Compétence M8
En fonction des projets déterminés autour de l’« Intégration de services dans un éco-système », savoir identifier, choisir (y-compris défendre) et adapter les solutions les plus appropriées pour les défis rencontrés
- Quoi :
Cette compétence consiste à identifier, sélectionner et adapter les solutions les plus adaptées pour intégrer des services dans un écosystème, en fonction des besoins spécifiques de chaque projet, tout en étant capable de justifier et de défendre ces choix face aux défis rencontrés.
- Comment :
- AR 1 : En étudiant les méthodologies proposées par divers experts, j'ai appris comment poser des questions plus ciblées lors d’un entretien pour démontrer mon intérêt et mieux comprendre les défis du recruteur. Cette approche, bien qu’encore théorique, m’aidera à choisir les meilleures stratégies de préparation et à m'adapter aux besoins des recruteurs.
Grâce à mon AR, voici les questions que j'ai posé durant l'entretien à Infomaniak :
Questions :
- Quels sont les projets principaux sur lesquels je pourrais être amené à travailler en tant que stagiaire frontend ?
- Dans le cadre de mon stage, je dois aussi réaliser un travail de bachelor. Est-ce que vous avez déjà une idée de sujet ou de projet qui pourrait correspondre à vos besoins ?
- Comment se déroule une journée type pour un développeur frontend chez Infomaniak ?
- Quelle est la taille de l'équipe frontend, et comment elle collabore avec les autres équipes, comme celles du backend, du design ou du produit ?
- Comment fonctionne la communication au sein de l'équipe ? Est-ce que vous travaillez en Scrum, Kanban, ou avec une autre méthodologie agile ? extrait du mail d'Infomaniak
extrait du mail d'Infomaniak
- AR 3 : En réfléchissant à la gestion des imprévus avec des outils comme GTD et la loi de Pareto, j’ai théorisé une approche plus systématique pour aborder des défis imprévus dans des projets futurs. Cette approche m’aidera à identifier rapidement les solutions les plus adaptées aux besoins du projet tout en prenant en compte les contraintes externes, comme les imprévus ou le stress, pour mieux prioriser mes efforts dans des situations complexes à venir.
 extrait de mon 3ème AR
extrait de mon 3ème AR
- LI 2 : Les différentes architectures neuronales présentées, comme les réseaux convolutionnels ou récurrents, mettent en évidence l’importance de choisir la bonne méthode selon la nature des données (images, texte, séquences). Par exemple, les couches convolutionnelles sont adaptées aux images, tandis que les LSTM sont idéaux pour des séquences complexes. Ce document fournit une base solide pour justifier des choix technologiques en fonction des contraintes et objectifs.
- Koloka : J'ai implémenté des composants modernes comme DialogTrigger et DialogClose pour gérer les modals dans la galerie interactive. J'ai également adapté des solutions CSS comme aspect-auto et object-contain pour améliorer le rendu des images verticales. Ces décisions montrent ma capacité à identifier et adapter les solutions appropriées aux défis techniques rencontrés.
 Extrait du composant shadcn que j'ai utilisé, récupéré le 14 janvier 2025 du https://ui.shadcn.com/docs/components/dialog (opens in a new tab)
Extrait du composant shadcn que j'ai utilisé, récupéré le 14 janvier 2025 du https://ui.shadcn.com/docs/components/dialog (opens in a new tab)
 Démonstration de mon implémentation sur Koloka
Démonstration de mon implémentation sur Koloka
 Démonstration de mon implémentation sur Koloka (ouverture d'une image)
Démonstration de mon implémentation sur Koloka (ouverture d'une image)
- DevPro : J’ai choisi avec mes camarades et intégré des solutions adaptées aux besoins spécifiques du projet, comme Rasa pour le développement du chatbot et Milvus pour le stockage vectoriel. J’ai également ajusté les configurations de ces outils pour surmonter des défis techniques, comme la compatibilité des versions et les problèmes de performances. Lors du problème de middleware sur Next.js, j'ai identifié l'utilisation incorrecte de l'Edge Runtime et ajusté la configuration pour utiliser nodejs uniquement sur les routes critiques. J'ai corrigé les redirections via useRouter et useState, et optimisé la gestion des erreurs d'authentification. La mise en place de SessionProvider a permis d'assurer un rendu sans erreurs et une gestion fluide des sessions utilisateur.
- CIMO : J’ai choisi des solutions adaptées pour répondre aux besoins du client, comme Random Forest pour les prédictions supervisées et K-Means pour le clustering des données. J’ai également ajusté les configurations des tableaux de bord pour améliorer la visualisation des données et enrichi les modèles avec des paramètres supplémentaires. Face à l'erreur dans mon modèle Random Forest, j'ai ajusté les valeurs manquantes en testant plusieurs options, comme la moyenne ou la valeur zéro, pour observer les impacts sur le modèle. J'ai également résolu le problème d'accès au tableau de bord en collaborant avec l'équipe pour rétablir la licence expirée de Microsoft Fabric, démontrant ma capacité à m'adapter et à résoudre les défis rencontrés. Ces choix ont permis d’optimiser les livrables tout en répondant aux problématiques identifiées.
from pyspark.sql import functions as F
from pyspark.sql.functions import year, month
# Charger le dataframe depuis Spark SQL
df = spark.sql("""
SELECT
SL.confidentiel1,
SL.confidentiel2,
SL.confidentiel3,
SL.confidentiel4,
SL.confidentiel5
FROM
LimsLakeHouse.silverlims AS SL
WHERE
SL.confidentiel IN ('confidentiel', 'confidentiel', 'confidentiel', 'confidentiel', 'confidentiel', 'confidentiel',
'confidentiel', 'confidentiel', 'confidentiel', 'confidentiel.', 'confidentiel', 'confidentiel-', 'confidentiel', 'confidentiel',
'confidentiel', 'confidentiel')
""")
# Filtrer les confidentiel d'intérêt
confidentiel_interet = [
"confidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel",
"confidentiel", "confidentiel", "confidentielconfidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel"
]
df_filtered = df.filter(F.col("confidentiel").isin(confidentiel_interet))
# Pivot des données pour avoir les paramètres comme colonnes
df_pivoted = df_filtered.groupBy("confidentiel", "confidentiel").pivot("confidentiel").agg(F.first("Valeur"))
# Liste des colonnes (confidentiel) à traiter
columns = [c for c in df_pivoted.columns if c not in ["confidentiel", "confidentiel"]]
# Remplacer les valeurs nulles ou égales à 0 par 0
df_filled = df_pivoted
for c in columns:
df_filled = df_filled.withColumn(
c,
F.when((F.col(c).isNull()) | (F.col(c) == 0), F.lit(0)).otherwise(F.col(c))
)
# Ajouter des colonnes temporelles
df_filled = df_filled.withColumn("Year", year(F.col("confidentiel")))
df_filled = df_filled.withColumn("Month", month(F.col("confidentiel")))
# Afficher les données pour vérification
display(df_filled)from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.evaluation import RegressionEvaluator
# Colonnes à utiliser comme features
feature_cols = [col for col in df_filled.columns if col not in ["confidentiel", "confidentiel", "confidentiel"]]
# Assembler les features en un vecteur
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_transformed = assembler.transform(df_filled)
# Diviser les données en jeu d'entraînement (80%) et de test (20%)
train_data, test_data = df_transformed.randomSplit([0.8, 0.2], seed=42)
# Initialiser le modèle Random Forest
rf = RandomForestRegressor(featuresCol="features", labelCol="confidentiel", numTrees=50)
# Entraîner le modèle
model = rf.fit(train_data)
# Faire des prédictions sur le jeu de test
predictions = model.transform(test_data)
# Évaluer le modèle avec RMSE
evaluator = RegressionEvaluator(labelCol="confidentiel", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error (RMSE): {rmse}")
# Importer Matplotlib pour les visualisations
import matplotlib.pyplot as plt
# Convertir les données Spark en Pandas pour visualisation
predictions_pd = predictions.select("Br-", "prediction").toPandas()
# Scatter plot des valeurs réelles vs prédites
plt.figure(figsize=(8, 6))
plt.scatter(predictions_pd["Br-"], predictions_pd["prediction"], alpha=0.5)
plt.xlabel("Valeurs réelles (Br-)")
plt.ylabel("Valeurs prédites")
plt.title("Comparaison des valeurs réelles vs prédites")
plt.show()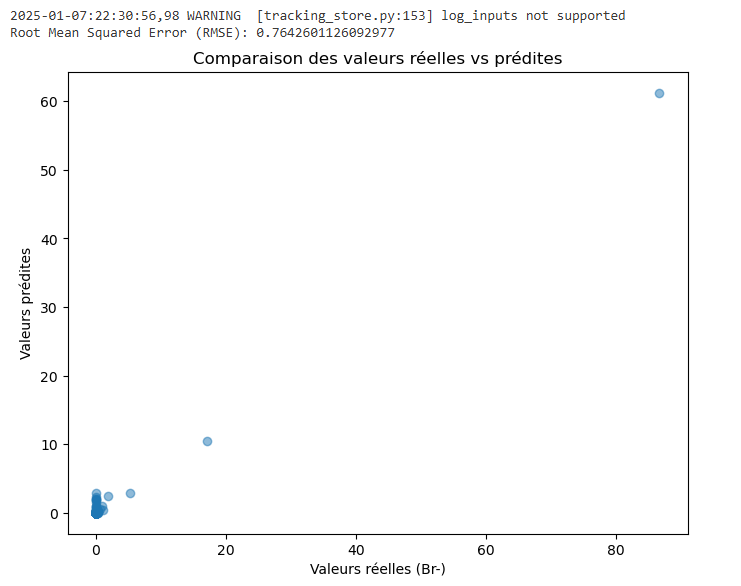 Extrait de mon modèle supervisé (Random forest)
Extrait de mon modèle supervisé (Random forest)
- Veille informatique : En utilisant DailyDev et en suivant des émissions comme Underscore, je prends l’initiative de me former en continu sur les nouvelles tendances technologiques, comme l'intelligence artificielle générative et les outils de collaboration avancés tels que Crew AI. Cela démontre ma capacité à apprendre de manière autonome sans dépendre exclusivement de cours ou de formations formelles.
 extrait de la page dailydev récupéré le 15 janvier 2025 de https://app.daily.dev/ (opens in a new tab)
extrait de la page dailydev récupéré le 15 janvier 2025 de https://app.daily.dev/ (opens in a new tab)
 extrait de la page youtube de Underscore_ récupéré le 15 janvier 2025 de https://www.youtube.com/@Underscore (opens in a new tab)_
extrait de la page youtube de Underscore_ récupéré le 15 janvier 2025 de https://www.youtube.com/@Underscore (opens in a new tab)_
- Pourquoi :
Savoir identifier, choisir et adapter les solutions dans un écosystème de services permet d'assurer la cohérence et la performance des projets en fonction des contraintes techniques, organisationnelles et métiers. Cela garantit l'utilisation de technologies adaptées aux besoins réels tout en optimisant les ressources disponibles. Cette compétence aide également à justifier les choix faits face aux parties prenantes, en expliquant l'impact des décisions sur les résultats attendus.
- Application pratique :
Dans le projet DevPro, l'intégration de Rasa pour le chatbot et Milvus pour le stockage vectoriel montre ma capacité à sélectionner des outils adaptés aux besoins spécifiques du projet. J'ai également résolu des problèmes liés aux versions de dépendances et ajusté la configuration du middleware de Next.js pour corriger les erreurs d'authentification. Dans le projet Koloka, j'ai choisi des composants comme DialogTrigger et DialogClose pour améliorer l'expérience utilisateur et adapté des classes CSS pour résoudre des problèmes de mise en page d'images verticales. Dans CIMO, l'utilisation des modèles Random Forest et K-Means a été choisie pour répondre aux besoins d'analyses prédictives et exploratoires des données. J'ai également ajusté les configurations des tableaux de bord pour enrichir la visualisation des résultats.
- Réflexion personnelle :
Ces expériences m'ont appris l'importance de bien comprendre les besoins métiers avant de choisir des outils ou des technologies pour s'assurer qu'ils répondent aux objectifs du projet. J'ai également pris conscience que la capacité à justifier et documenter ces choix est essentielle pour assurer l'adhésion des parties prenantes. Enfin, j'ai compris que l'adaptation continue des solutions en fonction des imprévus techniques ou organisationnels est une compétence clé pour garantir la réussite des projets.