Compétence B4
Connaître les impacts et les apports du Machine Learning et de l’intelligence artificielle sur le système d’information de l’entreprise
- Quoi :
Cette compétence consiste à comprendre comment le Machine Learning (ML) et l'intelligence artificielle (IA) peuvent transformer le système d'information d'une entreprise. Elle implique la capacité à évaluer l'apport de ces technologies en termes d'efficacité, d'automatisation des processus, d'amélioration de la prise de décision et de gestion des données. Cela inclut également la compréhension des implications techniques, économiques et éthiques de l'intégration de l'IA et du ML, ainsi que leur impact sur les processus métier, la gouvernance des données et la stratégie globale de l'entreprise.
- Comment :
- AR 1 : J’ai exploré les apports de l’intelligence artificielle dans la préparation d’entretien, en utilisant des outils comme ChatGPT pour affiner mes réponses et mieux comprendre les attentes du recruteur. Cette utilisation théorique de l'IA, bien que non encore appliquée dans un entretien réel, m’a permis de concevoir une approche plus structurée et efficace pour ma préparation à venir.
 Extrait de mon ar 1 (page 7)
Extrait de mon ar 1 (page 7)
-
LI 2 : Ce document décrit les concepts fondamentaux du Deep Learning, en expliquant les réseaux neuronaux artificiels et leurs applications pratiques, telles que la reconnaissance d'images ou de texte. Ces technologies, souvent intégrées dans des systèmes d’information modernes, améliorent les capacités de prédiction et d'automatisation. Les sections sur les autoencodeurs et les GAN démontrent l'impact direct des modèles génératifs sur l'optimisation des processus métier et l’innovation dans le traitement des données.
-
LI 3 : Le pilier 7 insiste sur la prise de décision éclairée par l'IA et le rôle central des algorithmes dans l’optimisation des processus et la personnalisation des offres. Cette lecture aide à comprendre comment l'IA améliore les performances des systèmes d’information en automatisant des tâches complexes et en réduisant les biais décisionnels.
 Extrait de ma LI (pilier 7)
Extrait de ma LI (pilier 7) -
LI IA (Camarade): La lecture de L’intelligence artificielle expliquée m’a permis de comprendre les concepts fondamentaux de l’IA et du machine learning, notamment les approches supervisées, non supervisées et par renforcement. Ce livre met en lumière l’impact stratégique des technologies d’IA sur les entreprises, telles que l’automatisation des processus, l’optimisation des flux de travail et la personnalisation des services. Les sections sur les GANs et les Transformers expliquent comment ces modèles innovants influencent les systèmes d’information modernes pour améliorer leur efficacité et leur compétitivité
-
LI ML (Camarade) : Ce document présente une initiation complète au Machine Learning, abordant des thématiques telles que la gestion des datasets, les étapes de développement d’un modèle prédictif et l’importance de l’évaluation des performances. Il met également l’accent sur les méthodologies nécessaires pour intégrer des modèles ML dans les systèmes d’information d’entreprise, renforçant leur capacité à traiter et analyser des données massives pour prendre des décisions éclairées.
-
DevPro : J’ai conçu et intégré un chatbot basé sur Rasa, utilisant des approches NLP et NLU pour répondre dynamiquement aux questions fréquentes sur les formations. J’ai comparé les approches embeddings et RAG (Retrieval-Augmented Generation) pour choisir la méthode la plus adaptée au projet, mettant en évidence l’apport des technologies d’IA pour améliorer la personnalisation et l’automatisation des interactions utilisateur. J'ai intégré l'API OpenAI et configuré les clés d'API dans un fichier .env pour protéger les informations sensibles. J'ai utilisé Milvus pour le stockage des données vectorielles et la gestion des résultats d'apprentissage, démontrant ainsi une intégration efficace des technologies basées sur l'intelligence artificielle dans un écosystème complexe.
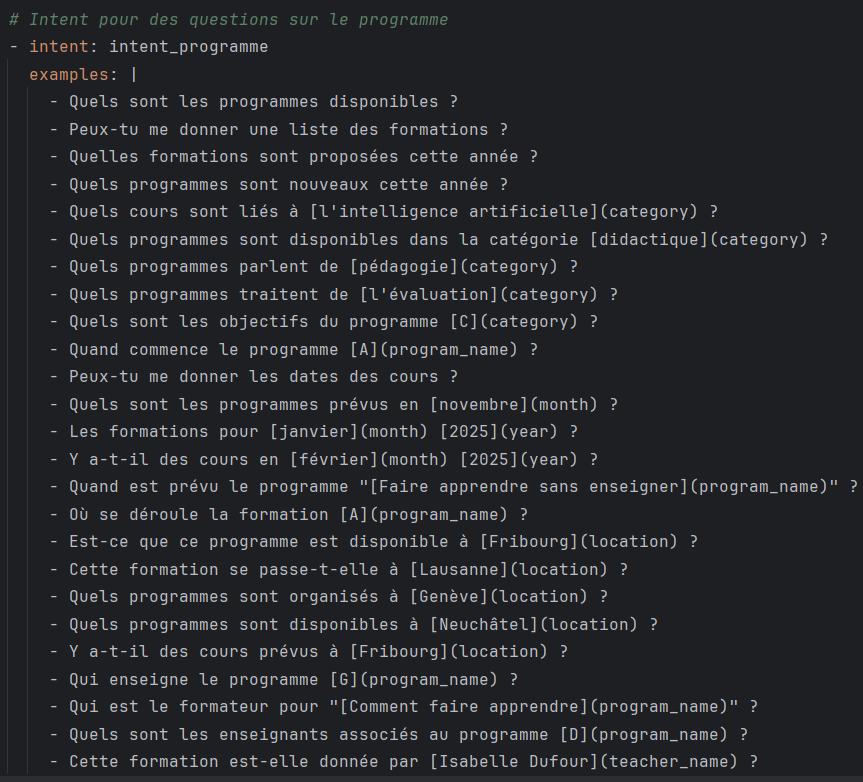 Extrait d'un des intents que j'ai fait
Extrait d'un des intents que j'ai fait
exemple de story :
- story: programme
steps:
- intent: intent_programme
- action: action_programme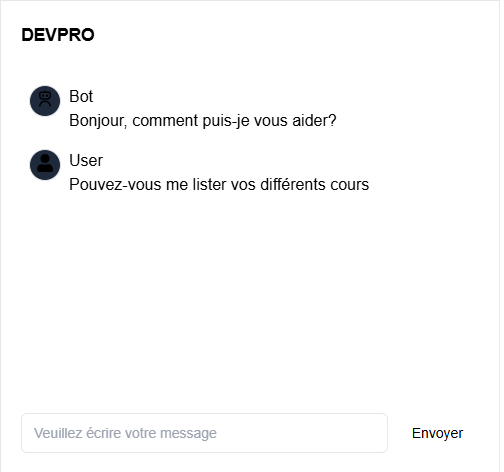 Extrait du chatbot DevPro, interface UI fait par Rafael Cardoso
Extrait du chatbot DevPro, interface UI fait par Rafael Cardoso
- CIMO : J’ai développé des modèles supervisés (Random Forest) et non supervisés (K-Means, DBSCAN) pour analyser les données et générer des insights exploitables. J'ai travaillé sur l'entraînement de ces modèles de machine learning, en testant différentes configurations et en effectuant le prétraitement des données. Ces modèles ont permis d’améliorer la prise de décision en automatisant les prédictions et en identifiant des clusters pertinents. J'ai également décrit le prétraitement des données et interprété les résultats dans la documentation du projet, démontrant ainsi une intégration efficace des modèles IA dans l'analyse des données pour renforcer les capacités du projet.
Modèle Random Forest :
from pyspark.sql import functions as F
from pyspark.sql.functions import year, month
# Charger le dataframe depuis Spark SQL
df = spark.sql("""
SELECT
SL.confidentiel1,
SL.confidentiel2,
SL.confidentiel3,
SL.confidentiel4,
SL.confidentiel5
FROM
LimsLakeHouse.silverlims AS SL
WHERE
SL.confidentiel IN ('confidentiel', 'confidentiel', 'confidentiel', 'confidentiel', 'confidentiel', 'confidentiel',
'confidentiel', 'confidentiel', 'confidentiel', 'confidentiel.', 'confidentiel', 'confidentiel-', 'confidentiel', 'confidentiel',
'confidentiel', 'confidentiel')
""")
# Filtrer les confidentiel d'intérêt
confidentiel_interet = [
"confidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel",
"confidentiel", "confidentiel", "confidentielconfidentiel", "confidentiel", "confidentiel", "confidentiel", "confidentiel"
]
df_filtered = df.filter(F.col("confidentiel").isin(confidentiel_interet))
# Pivot des données pour avoir les paramètres comme colonnes
df_pivoted = df_filtered.groupBy("confidentiel", "confidentiel").pivot("confidentiel").agg(F.first("Valeur"))
# Liste des colonnes (confidentiel) à traiter
columns = [c for c in df_pivoted.columns if c not in ["confidentiel", "confidentiel"]]
# Remplacer les valeurs nulles ou égales à 0 par 0
df_filled = df_pivoted
for c in columns:
df_filled = df_filled.withColumn(
c,
F.when((F.col(c).isNull()) | (F.col(c) == 0), F.lit(0)).otherwise(F.col(c))
)
# Ajouter des colonnes temporelles
df_filled = df_filled.withColumn("Year", year(F.col("confidentiel")))
df_filled = df_filled.withColumn("Month", month(F.col("confidentiel")))
# Afficher les données pour vérification
display(df_filled)from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.evaluation import RegressionEvaluator
# Colonnes à utiliser comme features
feature_cols = [col for col in df_filled.columns if col not in ["confidentiel", "confidentiel", "confidentiel"]]
# Assembler les features en un vecteur
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_transformed = assembler.transform(df_filled)
# Diviser les données en jeu d'entraînement (80%) et de test (20%)
train_data, test_data = df_transformed.randomSplit([0.8, 0.2], seed=42)
# Initialiser le modèle Random Forest
rf = RandomForestRegressor(featuresCol="features", labelCol="confidentiel", numTrees=50)
# Entraîner le modèle
model = rf.fit(train_data)
# Faire des prédictions sur le jeu de test
predictions = model.transform(test_data)
# Évaluer le modèle avec RMSE
evaluator = RegressionEvaluator(labelCol="confidentiel", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error (RMSE): {rmse}")
# Importer Matplotlib pour les visualisations
import matplotlib.pyplot as plt
# Convertir les données Spark en Pandas pour visualisation
predictions_pd = predictions.select("Br-", "prediction").toPandas()
# Scatter plot des valeurs réelles vs prédites
plt.figure(figsize=(8, 6))
plt.scatter(predictions_pd["Br-"], predictions_pd["prediction"], alpha=0.5)
plt.xlabel("Valeurs réelles (Br-)")
plt.ylabel("Valeurs prédites")
plt.title("Comparaison des valeurs réelles vs prédites")
plt.show()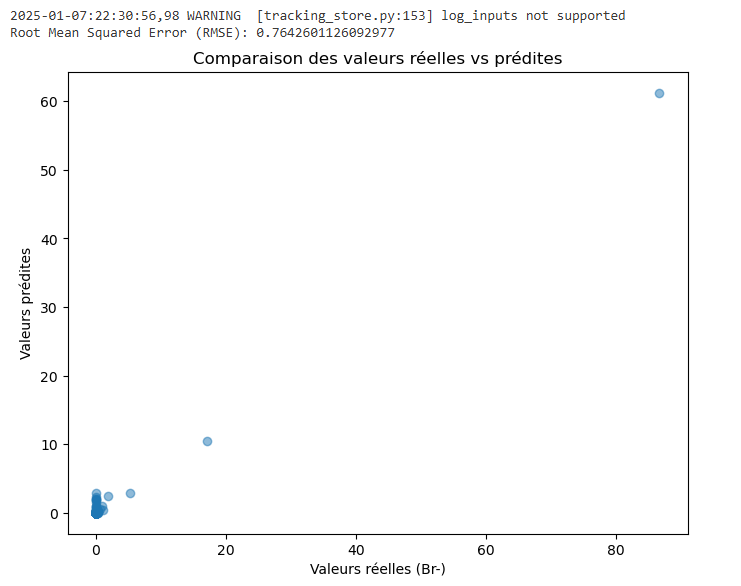 Extrait de mon modèle supervisé (Random forest)
Extrait de mon modèle supervisé (Random forest)
Modèle K-Means :
from pyspark.sql import functions as F
from pyspark.sql.functions import year, month
# Charger le dataframe depuis Spark SQL
df = spark.sql("""
SELECT
SL.confidentiel,
SL.confidentiel,
SL.confidentiel,
SL.confidentiel,
SL.confidentiel
FROM
LimsLakeHouse.silverlims AS SL
WHERE
SL.Parametre IN (confidentiel)
""")
# Filtrer les paramètres d'intérêt
parametres_interet = [
"confidentiel"
]
df_filtered = df.filter(F.col("confidentiel").isin(confidentiel_interet))
# Pivot des données pour avoir les paramètres comme colonnes
df_pivoted = df_filtered.groupBy("confidentiel", "confidentiel") \
.pivot("confidentiel") \
.agg(F.first("confidentiel"))
# Liste des colonnes (confidentiel) à traiter
columns = [c for c in df_pivoted.columns if c not in ["confidentiel", "confidentiel"]]
# Remplacer les nulls et les 0 par 0
df_replaced = df_pivoted
for col_ in columns:
df_replaced = df_replaced.withColumn(
col_,
F.when((F.col(col_).isNull()) | (F.col(col_) == 0), F.lit(0)).otherwise(F.col(col_))
)
# Ajouter des colonnes temporelles
df_filled = df_replaced \
.withColumn("Year", year(F.col("confidentiel"))) \
.withColumn("Month", month(F.col("confidentiel")))
# Vérification
display(df_filled)from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
from pyspark.ml.evaluation import ClusteringEvaluator
# Colonnes à utiliser comme features
feature_cols = [col for col in df_filled.columns if col not in ["confidentiel", "confidentiel", "Year", "Month"]]
# Assembler les features en un vecteur
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_transformed = assembler.transform(df_filled)
confidentiel
# Initialiser et entraîner le modèle K-Means
kmeans = KMeans(k=3, seed=42, featuresCol="features", predictionCol="cluster")
model = kmeans.fit(df_transformed)
# Faire des prédictions
df_clustered = model.transform(df_transformed)
# Afficher les données avec les clusters pour vérification
display(df_clustered)
df_clustered.groupBy("cluster").agg(
F.avg("confidentiel").alias("Avg_confidentiel"),
F.avg("OXYGENE").alias("Avg_Oxygen")
).show()
import matplotlib.pyplot as plt
# Convertir en Pandas pour visualisation
df_pandas = df_clustered.select("TEMPERATURE", "OXYGENE", "cluster").toPandas()
# Tracer les clusters
plt.figure(figsize=(8, 6))
for cluster in df_pandas["cluster"].unique():
cluster_data = df_pandas[df_pandas["cluster"] == cluster]
plt.scatter(cluster_data["TEMPERATURE"], cluster_data["OXYGENE"], label=f"Cluster {cluster}")
plt.xlabel("Temperature")
plt.ylabel("Oxygen")
plt.title("Clustering with K-Means")
plt.legend()
plt.show()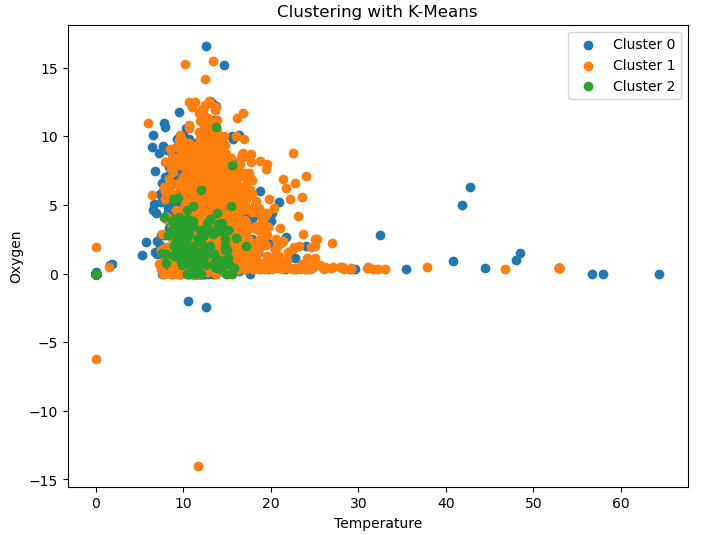 Extrait de mon modèle non-supervisé (K-Means)
Extrait de mon modèle non-supervisé (K-Means)
- SF-ML : La formation a couvert la gestion des datasets, la validation croisée, et l’importance d’un pipeline propre pour garantir la fiabilité des résultats. Ces éléments sont essentiels pour intégrer le ML dans un projet SI tout en assurant la maintenance et l'amélioration continue des modèles
- Apple Watch : J'ai pris l'initiative d'extraire les données de mon Apple Watch concernant uniquement le rythme cardiaque pour m'entraîner à construire des modèles de machine learning supervisé et non supervisé. J'ai nettoyé et préparé ces données, puis expérimenté avec différents algorithmes pour effectuer des prédictions et des regroupements. Cette démarche personnelle démontre ma capacité à apprendre de manière autonome et à me perfectionner dans l'application pratique de l'intelligence artificielle.
Modèle K-Means :
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
def unsupervised_analysis(file="final_data.csv"):
df = pd.read_csv(file)
if "BPM" not in df.columns:
print("Colonne BPM introuvable dans le fichier.")
return
# Création de quelques features
df["BPM_diff"] = df["BPM"].diff().fillna(0)
df["BPM_rolling_mean"] = df["BPM"].rolling(window=5, min_periods=1).mean()
df["BPM_rolling_std"] = df["BPM"].rolling(window=5, min_periods=1).std().fillna(0)
df.dropna(inplace=True)
features = ["BPM", "BPM_diff", "BPM_rolling_mean", "BPM_rolling_std"]
X = df[features].values
# 1) Clustering (K-Means)
k = 3 # Nombre de clusters
kmeans = KMeans(n_clusters=k, random_state=42)
df["Cluster"] = kmeans.fit_predict(X)
print("\n--- Clustering K-Means ---")
print(df.groupby("Cluster")[features].mean())
# Visualisation simple (sur 2 features pour un scatterplot)
plt.figure(figsize=(7, 5))
plt.scatter(df["BPM"], df["BPM_rolling_mean"], c=df["Cluster"], cmap="viridis")
plt.title("K-Means: BPM vs. BPM_rolling_mean")
plt.xlabel("BPM")
plt.ylabel("BPM Rolling Mean")
plt.grid(True)
plt.show()
# 2) Détection d'anomalies (IsolationForest)
iso = IsolationForest(contamination=0.01, random_state=42)
iso.fit(X)
df["anomaly_score"] = iso.decision_function(X)
df["is_anomaly"] = iso.predict(X) # 1 = normal, -1 = anomalie
anomalies = df[df["is_anomaly"] == -1]
print("\n--- Anomalies détectées ---")
print(anomalies.head())
print(f"Nombre total d'anomalies: {len(anomalies)}")
# Visualisation des anomalies
plt.figure(figsize=(10, 4))
plt.plot(df.index, df["BPM"], label="BPM", color="blue")
plt.scatter(anomalies.index, anomalies["BPM"], color="red", label="Anomalies")
plt.title("Détection d'anomalies (IsolationForest)")
plt.xlabel("Index")
plt.ylabel("BPM")
plt.legend()
plt.grid(True)
plt.show()
# Appel de la fonction
unsupervised_analysis("final_data.csv") Extrait de mon modèle non-supervisé (K-Means)
Extrait de mon modèle non-supervisé (K-Means)
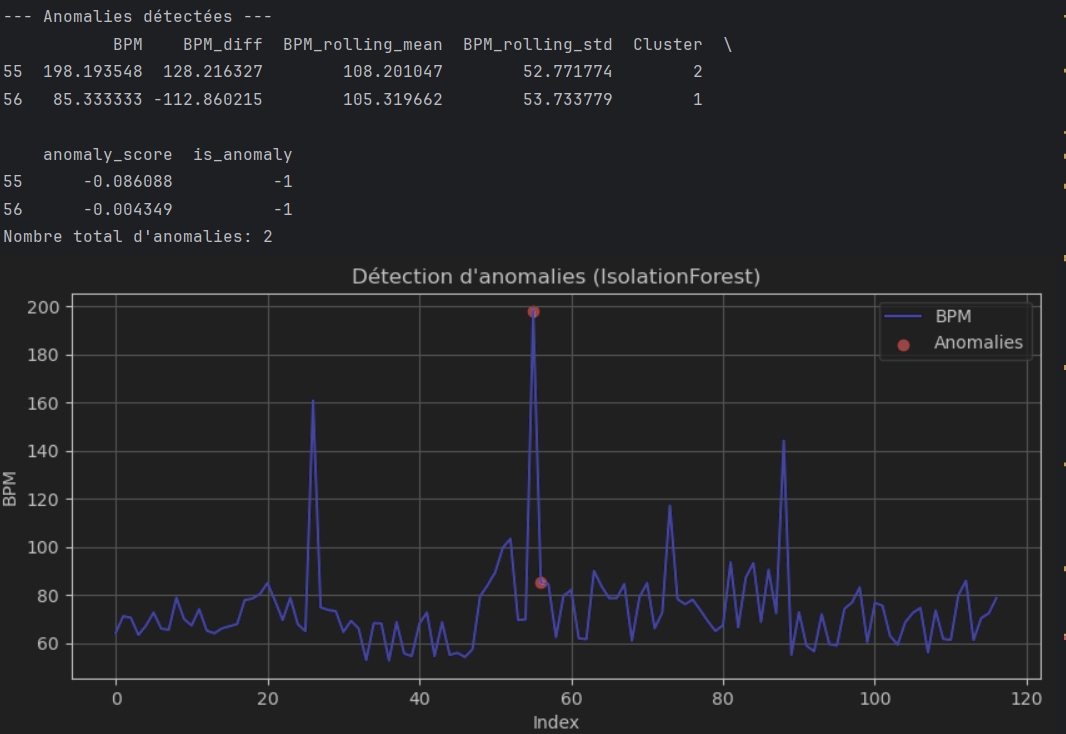 Extrait de mon modèle non-supervisé (K-Means)
Extrait de mon modèle non-supervisé (K-Means)
Je pense que le modèle K-Means peut être intéressant pour avoir une première exploration des données BPM provenant de mon Apple Watch, mais il n’est pas forcément le plus adapté. Les variations de BPM sont souvent influencées par des facteurs temporels comme l'activité physique ou le stress, ce qui rend les hypothèses du K-Means (clusters sphériques et homogènes) moins pertinentes. Je pourrais envisager des modèles plus adaptés aux séries temporelles, comme ARIMA ou des réseaux neuronaux récurrents, pour mieux capturer les variations et les comportements complexes de mes données.
Modèle Regression Linéaire :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
def create_time_features(df, max_lag=3, rolling_window=5):
"""
Crée des features basées sur le BPM :
1) Lags multiples (BPM_lag1, BPM_lag2, etc.)
2) Rolling mean et rolling std sur une fenêtre donnée
3) BPM_diff (différence entre t et t-1)
4) BPM_future (décalage de -1 pour prédire le BPM suivant)
"""
# 1) Création des lags
for lag in range(1, max_lag+1):
df[f"BPM_lag{lag}"] = df["BPM"].shift(lag)
# 2) Rolling mean et std
df["BPM_rolling_mean"] = df["BPM"].rolling(window=rolling_window, min_periods=1).mean()
df["BPM_rolling_std"] = df["BPM"].rolling(window=rolling_window, min_periods=1).std().fillna(0)
# 3) Différence instantanée
df["BPM_diff"] = df["BPM"].diff().fillna(0)
# 4) Cible : BPM du point suivant
df["BPM_future"] = df["BPM"].shift(-1)
# Supprimer les lignes NaN (en particulier les premières lignes à cause des lags
# et la dernière pour BPM_future)
df.dropna(inplace=True)
return df
def train_test_split_time_based(df, split_ratio=0.8):
"""
Sépare chronologiquement le dataset :
- train = 0 à split_index
- test = split_index à fin
"""
split_index = int(len(df) * split_ratio)
train_df = df.iloc[:split_index].copy()
test_df = df.iloc[split_index:].copy()
return train_df, test_df
def supervised_regression_time_series(
file_path="final_data.csv",
max_lag=3,
rolling_window=5,
split_ratio=0.8,
use_gridsearch=False
):
"""
Pipeline complet :
1) Lecture du CSV contenant une colonne 'BPM'
2) Création de features (lags, rolling, diff, BPM_future)
3) Split train/test chronologique
4) Entraînement d'un RandomForestRegressor
(option GridSearchCV pour ajuster hyperparamètres)
5) Prédiction + Évaluation (MSE, R2)
6) Visualisation (courbes y_test vs y_pred)
"""
# 1) Lecture des données
df = pd.read_csv(file_path)
if "BPM" not in df.columns:
print("Erreur : colonne 'BPM' introuvable dans le fichier.")
return None
# 2) Création des features
df = create_time_features(df, max_lag=max_lag, rolling_window=rolling_window)
# 3) Split chronologique
train_df, test_df = train_test_split_time_based(df, split_ratio=split_ratio)
# 4) Préparation X, y
feature_cols = [col for col in train_df.columns
if col not in ("BPM_future", "BPM", "datetime")] # exclure BPM si besoin
# Exemple : on garde BPM + BPM_lag1..n, BPM_rolling_mean, BPM_rolling_std, BPM_diff
X_train = train_df[feature_cols].values
y_train = train_df["BPM_future"].values
X_test = test_df[feature_cols].values
y_test = test_df["BPM_future"].values
# Modèle
model = RandomForestRegressor(n_estimators=100, random_state=42)
if use_gridsearch:
# Exemple d'espace d'hyperparamètres
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_leaf': [1, 2, 5]
}
# On utilise TimeSeriesSplit pour rester cohérent
tscv = TimeSeriesSplit(n_splits=3)
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
scoring='r2',
cv=tscv,
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print("Meilleurs paramètres (GridSearch) :", grid_search.best_params_)
model = grid_search.best_estimator_
else:
model.fit(X_train, y_train)
# 5) Prédiction et évaluation
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("=== Évaluation (portion Test) ===")
print(f" - MSE = {mse:.3f}")
print(f" - R^2 = {r2:.3f}")
# 6) Visualisation simple
plt.figure(figsize=(10, 5))
plt.plot(test_df.index, y_test, label="BPM futur (réel)", color='blue')
plt.plot(test_df.index, y_pred, label="BPM prédit", color='orange')
plt.title("Comparaison du BPM réel vs. prédiction (Test set)")
plt.xlabel("Index (temps)")
plt.ylabel("BPM")
plt.legend()
plt.grid(True)
plt.show()
return model
if __name__ == "__main__":
model = supervised_regression_time_series(
file_path="final_data.csv",
max_lag=3,
rolling_window=5,
split_ratio=0.8,
use_gridsearch=False
)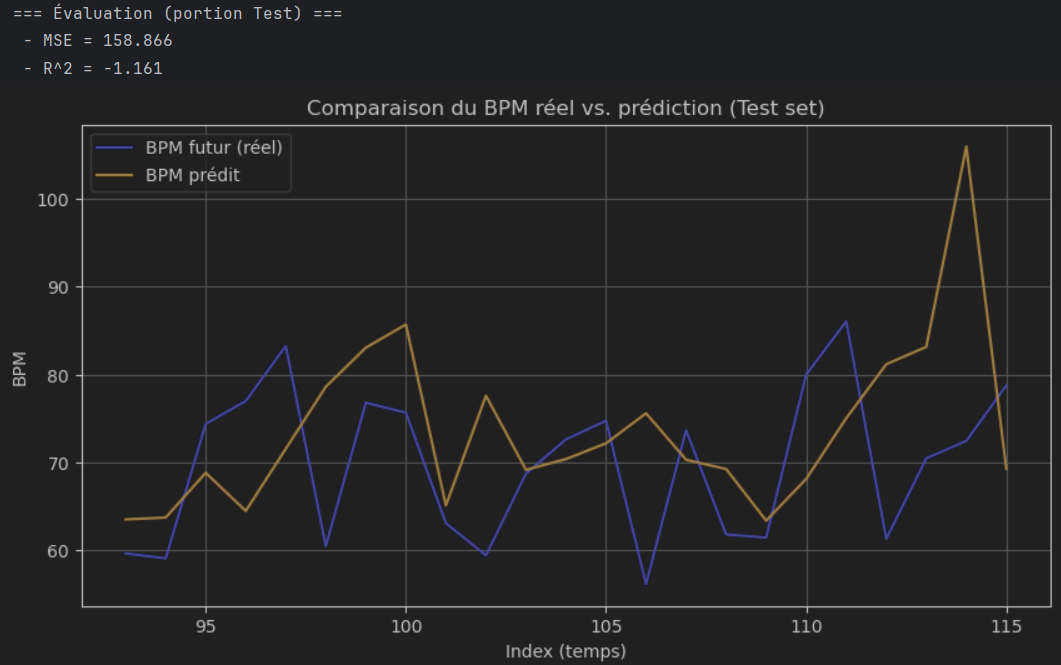 Extrait de mon modèle supervisé régression linéaire
Extrait de mon modèle supervisé régression linéaire
Je pense que ce modèle est bien adapté pour prédire les BPM à partir des données de mon Apple Watch. Il utilise des caractéristiques temporelles pertinentes et un Random Forest pour fournir des prédictions fiables. Cependant, des modèles plus avancés comme les LSTM pourraient mieux capturer les dynamiques complexes des séries temporelles.
modèle DBSCAN :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
def create_features_for_clustering(df):
"""
Exemple de fonction pour sélectionner ou créer quelques features
pour un clustering non supervisé (DBSCAN).
Suppose qu'on a déjà une colonne 'BPM' dans df.
"""
# On peut garder seulement la colonne BPM ou ajouter d'autres features
# (rolling mean, diff, etc.) si on veut un clustering plus riche.
# Par exemple :
df["BPM_diff"] = df["BPM"].diff().fillna(0)
df["BPM_rolling_mean"] = df["BPM"].rolling(window=5, min_periods=1).mean()
df["BPM_rolling_std"] = df["BPM"].rolling(window=5, min_periods=1).std().fillna(0)
df.dropna(inplace=True)
# Sélection des features pour le clustering
features = ["BPM", "BPM_diff", "BPM_rolling_mean", "BPM_rolling_std"]
return df[features]
def dbscan_clustering(file_path="final_data.csv", eps=5, min_samples=5):
"""
1) Lecture du CSV contenant 'BPM'
2) Création/ sélection de features
3) Standardisation des données
4) Application DBSCAN
5) Affichage du nombre de clusters et visualisation
"""
# 1) Lecture
df = pd.read_csv(file_path)
if "BPM" not in df.columns:
print("Colonne BPM introuvable. Vérifiez votre fichier.")
return
# 2) Création/ sélection de features
X = create_features_for_clustering(df)
# X est un DataFrame avec columns = [BPM, BPM_diff, BPM_rolling_mean, BPM_rolling_std, ...]
# 3) Standardisation
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 4) DBSCAN
# eps = distance max pour former un cluster
# min_samples = nombre minimum de points pour être considéré comme cluster dense
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
clusters = dbscan.fit_predict(X_scaled)
# Ajout du cluster dans le DataFrame
X["Cluster"] = clusters
# 5) Affichage
# Nombre de clusters trouvés (valeur -1 = bruit / outlier)
cluster_labels = np.unique(clusters)
n_clusters = len(cluster_labels[cluster_labels != -1]) # on exclut le -1 (bruit)
print(f"Nombre de clusters (hors bruit) = {n_clusters}")
print(f"Labels de clusters trouvés = {cluster_labels}")
print(X.groupby("Cluster").mean())
# Visualisation 2D (on ne peut tracer que 2 features à la fois)
# Exemple : BPM vs BPM_diff colorés par cluster
plt.figure(figsize=(8, 6))
plt.scatter(X["BPM"], X["BPM_diff"], c=X["Cluster"], cmap="rainbow", s=20)
plt.title("DBSCAN Clustering : BPM vs BPM_diff")
plt.xlabel("BPM")
plt.ylabel("BPM_diff")
plt.colorbar(label="Cluster")
plt.show()
return X # on retourne le DataFrame avec la colonne "Cluster"
if __name__ == "__main__":
result = dbscan_clustering(
file_path="final_data.csv",
eps=5, # Distance maximale pour la densité
min_samples=5 # Nombre min de points dans le voisinage pour former un cluster
)
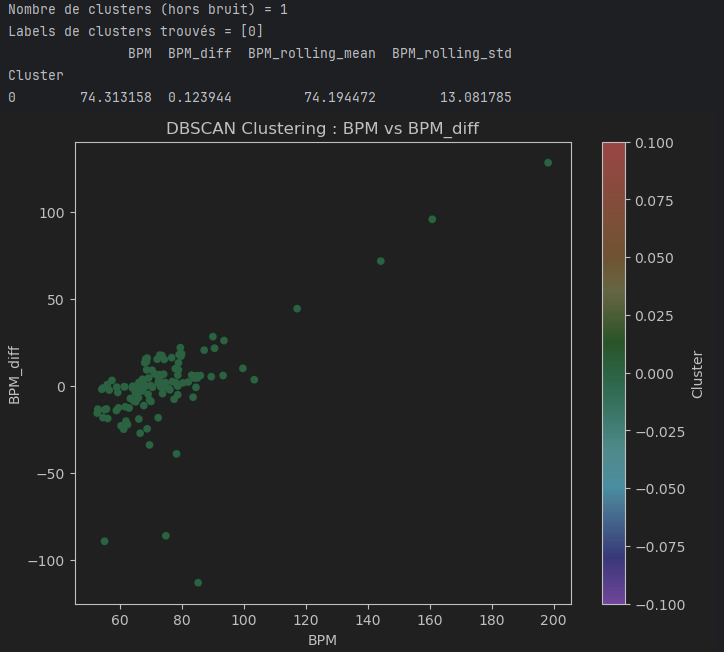 Extrait de mon modèle non-supervisé (DBSCAN)
Extrait de mon modèle non-supervisé (DBSCAN)
Je pense que ce modèle utilisant DBSCAN est bien adapté pour explorer les données BPM de mon Apple Watch. Contrairement à K-Means, il détecte des clusters de formes arbitraires et identifie les points isolés comme du bruit, ce qui convient bien aux données biométriques souvent hétérogènes.
- Pourquoi :
Comprendre les impacts et les apports du Machine Learning (ML) et de l'intelligence artificielle (IA) sur le système d’information permet d’identifier les opportunités d'automatisation, d'amélioration de la prise de décision et de personnalisation des services. Cela aide également à anticiper les défis liés à la gestion des données, aux biais algorithmiques et aux enjeux éthiques, tout en garantissant un alignement des outils d'IA avec les objectifs stratégiques de l'entreprise. Cette compétence est essentielle pour exploiter pleinement le potentiel de l'IA tout en optimisant la gestion des ressources et en améliorant l'efficacité globale des processus métiers.
- Application pratique :
Dans le projet DevPro, l'intégration d'un chatbot intelligent basé sur Rasa et l'API OpenAI a permis de créer des interactions personnalisées et automatisées avec les utilisateurs, démontrant l'apport de l'IA pour simplifier et enrichir l'expérience utilisateur. Le stockage des données vectorielles dans Milvus a renforcé la capacité du système à gérer de grandes quantités de données textuelles et à fournir des réponses précises. Pour le projet CIMO, les modèles supervisés (Random Forest) et non supervisés (K-Means, DBSCAN) ont été utilisés pour automatiser l'analyse des données environnementales et fournir des prévisions plus précises, améliorant ainsi la prise de décision. La formation ML m'a permis de consolider mes connaissances sur l'importance de la gestion des datasets et des pipelines pour assurer la qualité et la fiabilité des modèles de machine learning.
- Réflexion personnelle :
Ces expériences m'ont permis de mieux comprendre comment le ML et l'IA peuvent transformer un système d'information en augmentant sa capacité à traiter des volumes importants de données et à automatiser des tâches complexes. J'ai également réalisé l'importance du prétraitement des données pour garantir des résultats fiables et éviter des biais dans les prédictions. De plus, la nécessité de documenter chaque étape de l'intégration des modèles m'a sensibilisé aux enjeux de transparence et de gouvernance des données. Ces projets m'ont donné une vision plus claire des apports stratégiques de l'IA dans un environnement métier et m'ont motivé à poursuivre mon apprentissage dans ce domaine pour améliorer mes capacités d'intégration de solutions IA dans des systèmes d'information complexes.
Etre capable d’intégrer tous les processus de développement logiciel et de gestion du cycle de vie des données dans des projets complexes
- Quoi :
Cette compétence consiste à coordonner et intégrer de manière fluide les processus de développement logiciel (DevOps, CI/CD) et la gestion du cycle de vie des données (Data Lifecycle Management - DLM) dans des projets complexes. Cela implique de gérer chaque étape du développement, depuis la conception jusqu’au déploiement, tout en assurant une gestion efficace des données, incluant la collecte, le stockage, l'analyse, la protection et la suppression des données. Cette compétence nécessite de maîtriser les outils et méthodologies nécessaires pour garantir l'efficacité, la conformité et la sécurité des projets, tout en tenant compte des exigences de performance et de scalabilité.
- Comment :
- AR 1 : Bien que cette compétence soit principalement théorique dans cet article, j’ai pris conscience de l'importance d’intégrer des méthodologies structurées, comme la méthode STAR pour répondre aux questions comportementales, afin d’appliquer une approche plus professionnelle et réfléchie lors de mes futurs entretiens.
 Extrait de mon ar 1 (page 7)
Extrait de mon ar 1 (page 7)
- SF-ML : La formation a couvert la gestion des datasets, la validation croisée, et l’importance d’un pipeline propre pour garantir la fiabilité des résultats. Ces éléments sont essentiels pour intégrer le ML dans un projet SI tout en assurant la maintenance et l'amélioration continue des modèles.
- Koloka : J'ai conçu et fetché les données depuis une table Strapi, corrigé des erreurs liées à la casse des noms générés automatiquement, et collaboré avec Térence pour déboguer un schéma Strapi. Ces actions montrent ma capacité à gérer le cycle de vie des données dans un environnement complexe.
- DevPro : J'ai intégré tous les processus du cycle de vie du développement logiciel, allant de l'analyse des besoins jusqu'au déploiement. J'ai utilisé GitHub Actions pour le CI/CD, Docker pour l'uniformisation de l'environnement, et Public Cloud pour le déploiement (développement et production). La gestion du projet suivait la méthodologie Scrum, avec des sprints planifiés, des reviews et des rétrospectives pour ajuster le backlog. J'ai également configuré des bases de données vectorielles Milvus pour stocker et gérer les données d'apprentissage du chatbot, avec un suivi des modifications via des pipelines Azure DevOps.
 extrait d'azure devops du projet devpro
extrait d'azure devops du projet devpro
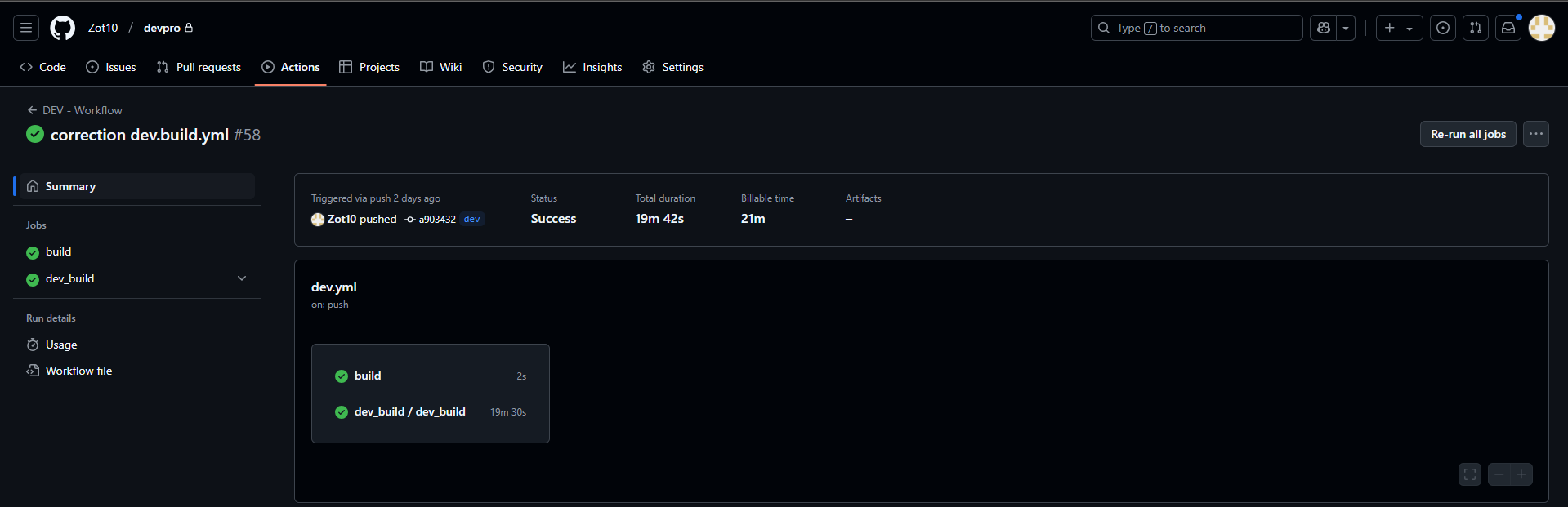 extrait des actions sur github
extrait des actions sur github
 extrait de mon workflow CI/CD
extrait de mon workflow CI/CD
 extrait de connexion sur l'instance public cloud d'Infomaniak
extrait de connexion sur l'instance public cloud d'Infomaniak
- CIMO : J'ai intégré une gestion complète du cycle de vie des données en utilisant des tableaux de bord interactifs et des modèles de machine learning supervisés et non supervisés. Les données brutes ont été prétraitées, nettoyées, puis transformées en features pour entraîner des modèles (Random Forest et DBSCAN). Le projet a suivi une méthodologie hybride Scrum + Waterfall, combinée à un Kanban pour gérer les tâches. La mise à jour des données et la gestion des résultats étaient automatisées via Azure DevOps, garantissant un suivi fluide du projet.
Les modèles ci-dessus sont des extraits de mon modèle supervisé (Random Forest) et non supervisé (K-Means) que j'ai fait pour le projet CIMO.
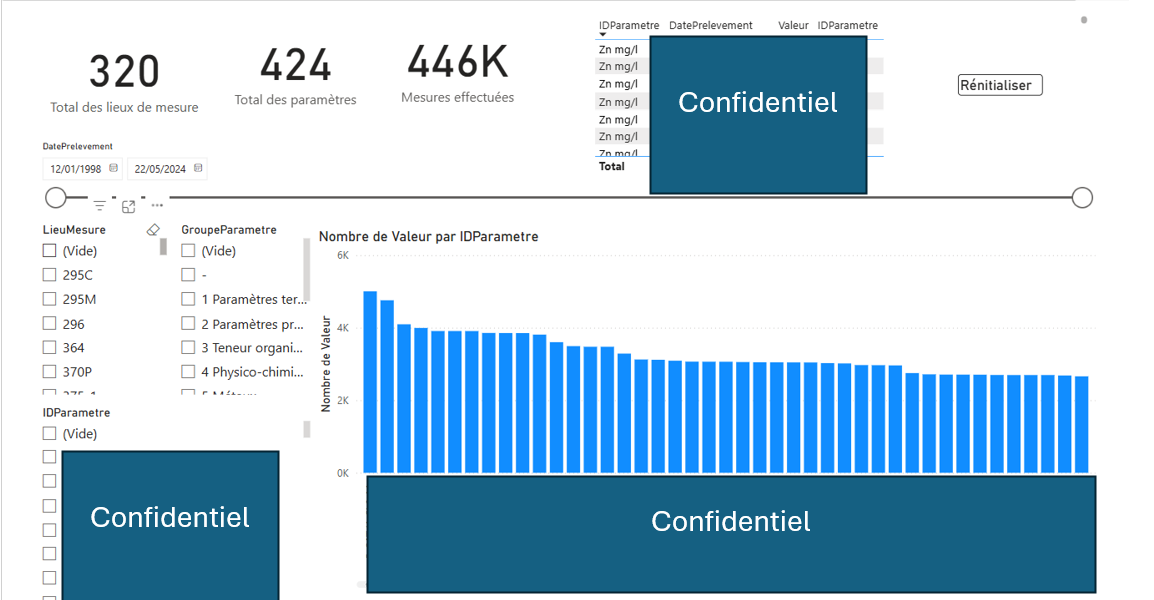 extrait du dashboard du projet CIMO
extrait du dashboard du projet CIMO
 ETL modèle médaillon Bronze => Silver
ETL modèle médaillon Bronze => Silver
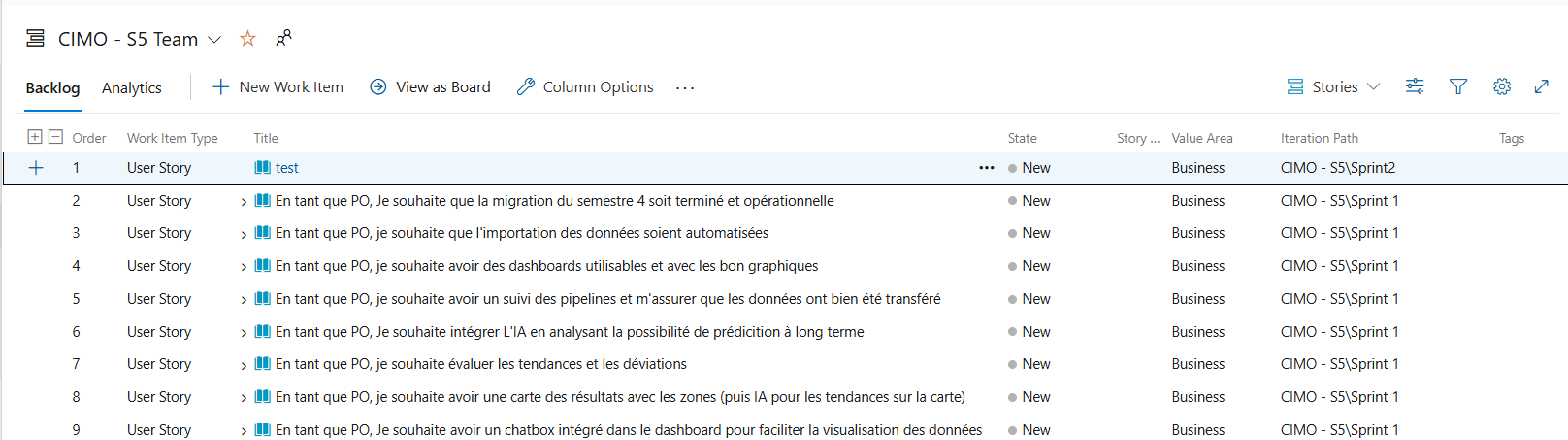 extrait de notre méthodologie agile sur azure devops
extrait de notre méthodologie agile sur azure devops
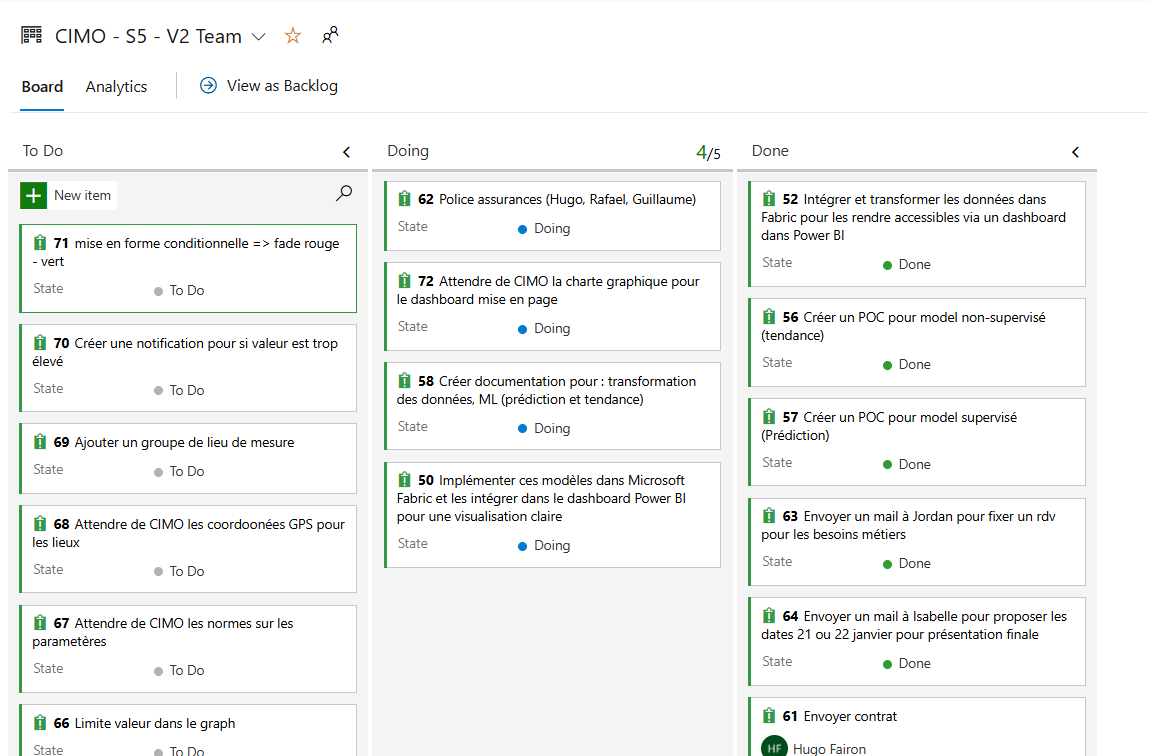 extrait de notre méthodologie hybride sur azure devops
extrait de notre méthodologie hybride sur azure devops
- Infomaniak : Dans le cadre du challenge Angular, j'ai intégré les différentes étapes du cycle de vie du développement logiciel : analyse des besoins, création des composants Angular (list-page.component et species.service.ts), implémentation des appels API, tests end-to-end avec Cypress. J'ai utilisé Git pour la gestion des versions.
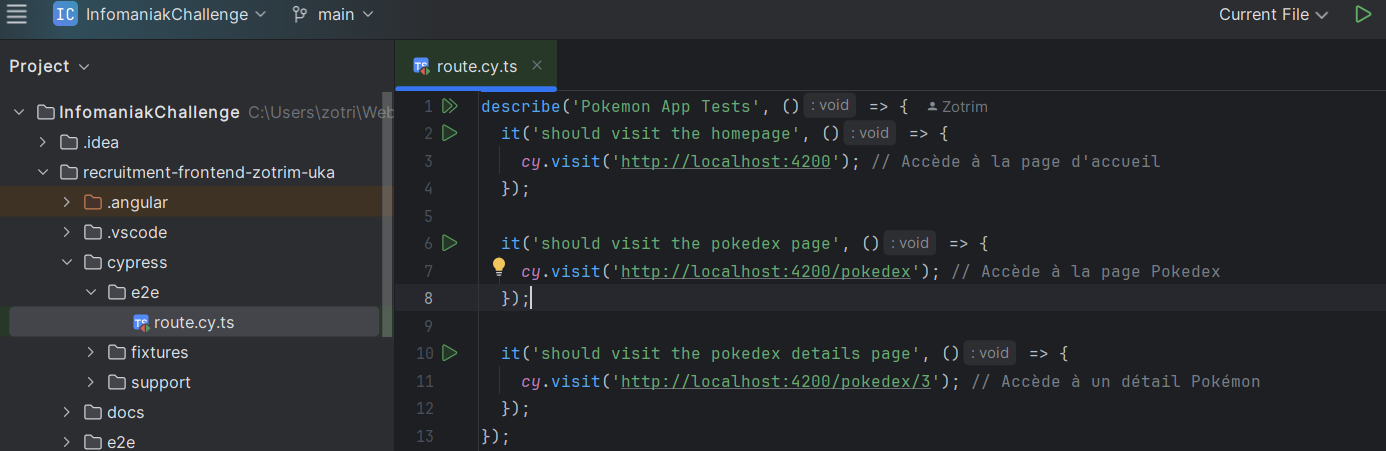 extrait de mon code (cypress) durant le challenge infomaniak
extrait de mon code (cypress) durant le challenge infomaniak
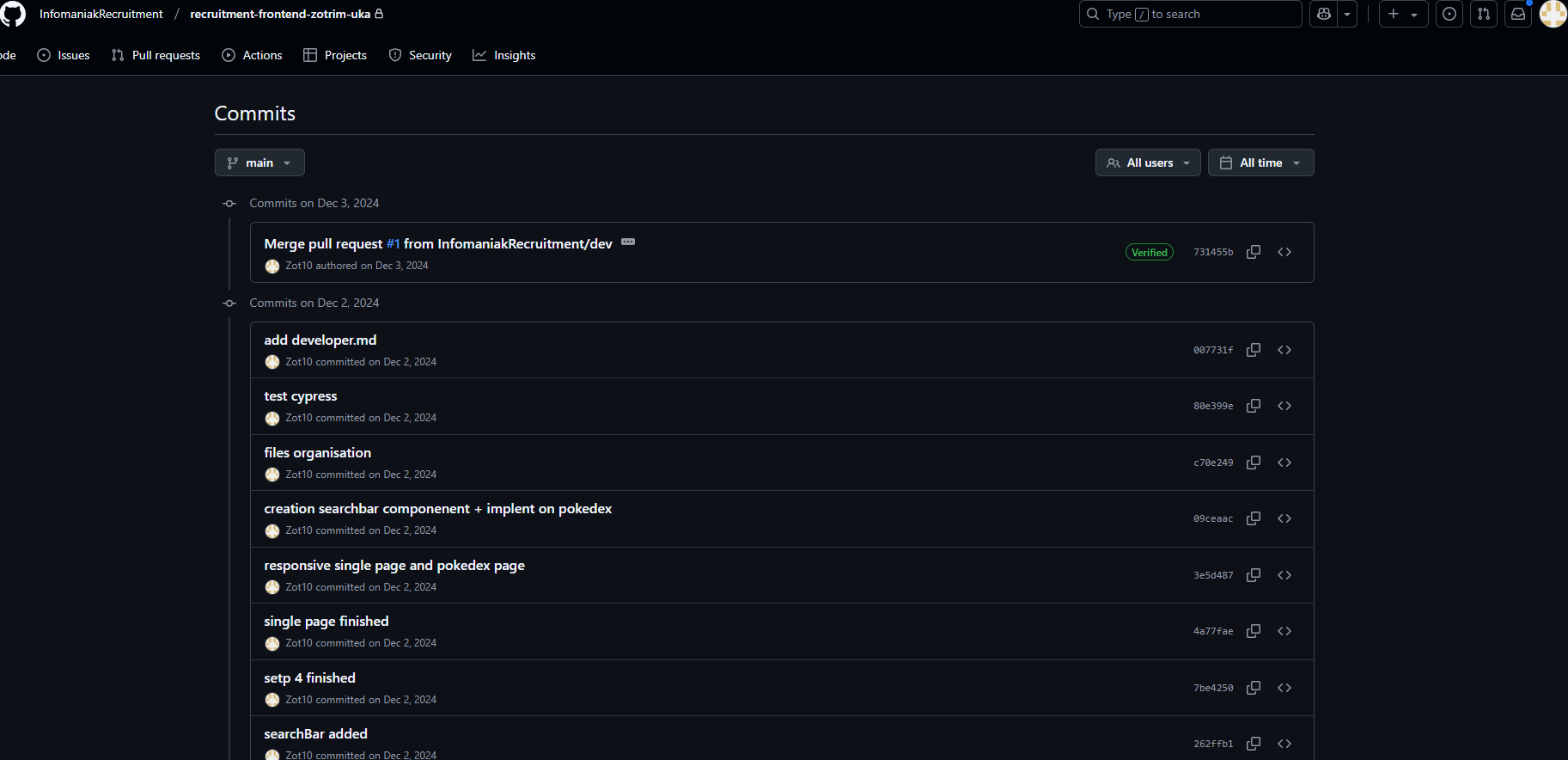 extrait de mon github pour le challenge infomaniak
extrait de mon github pour le challenge infomaniak
getSpecies(): Observable<Pokemon[]> {
return this.http.get<{ data: any[] }>(`${environment.apiUrl}/species`).pipe(
map((response) => {
return response.data.map(
item =>
new Pokemon(
item.id,
item.name,
item.image,
Array.isArray(item.types) ? item.types : []
)
);
})
);
}- Pourquoi :
L'intégration des processus de développement logiciel et de gestion du cycle de vie des données dans des projets complexes permet de garantir la cohérence et la performance des livrables. Cela assure un suivi rigoureux de toutes les étapes, depuis la collecte des données jusqu'au déploiement des fonctionnalités, tout en facilitant la maintenance et l'amélioration continue des systèmes. Une bonne gestion du cycle de vie des données réduit les risques liés à la qualité des données, à la sécurité et à la conformité aux exigences réglementaires.
-
Application pratique : Dans le projet DevPro, l'utilisation de GitHub Actions et Docker pour automatiser le build et le déploiement a permis de structurer un workflow CI/CD complet. Cela a facilité la gestion des environnements de développement et de production en garantissant une uniformisation des configurations. Sur Koloka, la récupération et le traitement des données via Strapi ont illustré ma capacité à intégrer la gestion des données dans un environnement front-end dynamique, en corrigeant des erreurs liées aux conventions de nommage pour garantir l'intégrité des données affichées.
-
Réflexion personnelle :
Ces expériences m'ont montré l'importance d'une approche unifiée pour intégrer les processus de développement et la gestion des données dans des projets complexes. J'ai appris que chaque étape doit être documentée et automatisée autant que possible pour éviter des erreurs et assurer la scalabilité du projet. J'ai également pris conscience que la qualité des données joue un rôle clé dans la fiabilité des résultats et que des outils comme Milvus et Azure DevOps peuvent simplifier la gestion des cycles de vie dans des contextes multi-équipe et multi-environnement.