Compétence M7
En fonction des projets déterminés autour de l’« Intégration de services dans un écosystème », connaître, appliquer et mettre en œuvre les méthodologies et les outils adaptés
- Quoi :
Cette compétence consiste à sélectionner et utiliser les méthodologies et outils appropriés pour intégrer efficacement des services au sein d'un écosystème, en fonction des besoins spécifiques de chaque projet. Elle implique la mise en œuvre de solutions permettant l'interopérabilité et la cohésion entre différents services et applications.
- Comment :
- AR 1 : En théorisant l’utilisation de ChatGPT pour la préparation d’entretien, j'ai intégré des méthodologies et des outils adaptés. J'ai utilsé chatGpt pour me préparer à l'entretien pour Infomaniak. J'ai pu anticiper les questions et améliorer la structure de mes réponses pour des entretiens futurs.
 Extrait de mon ar 1 (page 7)
Extrait de mon ar 1 (page 7)
- AR 3 : J’ai étudié des méthodologies comme la méthode des 20 heures et GTD, qui sont des outils adaptés pour structurer l'apprentissage et gérer efficacement les priorités, même dans des conditions stressantes. Bien que je n’aie pas encore appliqué ces théories dans un projet réel, elles me serviront de guide pour mieux organiser mes tâches futures, optimiser mes processus de travail et mieux intégrer des services dans des projets plus complexes à venir.
 extrait de mon 3ème article réflexif
extrait de mon 3ème article réflexif
- LI 2 : Le cours explore des outils pratiques comme la rétropropagation et la descente de gradient pour optimiser les réseaux neuronaux, qui peuvent être intégrés dans des pipelines de machine learning d’entreprise. Les explications sur les architectures modulaires montrent comment combiner différentes couches (convolutionnelles, récurrentes, etc.) pour répondre à des besoins spécifiques, comme l’analyse d’images ou de séquences, dans un environnement de services interconnectés.
- LI 3 : Le pilier 8 montre comment la technologie agit comme un catalyseur en intégrant des services via des architectures événementielles (EDA) et des API. Cette intégration permet une meilleure interopérabilité des services dans l'écosystème IT.
 Extrait de ma LI 3 (pilier 8)
Extrait de ma LI 3 (pilier 8)
- Koloka : J'ai utilisé la méthodologie Scrum pour organiser le projet en sprints, avec des User Stories, des sprint reviews, et des sessions de planification en collaboration avec l'équipe. J'ai également intégré et corrigé des éléments dans Strapi, notamment la création de tables, le fetch des données et la résolution de bugs. Par ailleurs, j'ai utilisé des composants modernes comme DialogTrigger pour implémenter une galerie interactive, démontrant ma capacité à utiliser des outils adaptés à un écosystème complexe. Pour le développement des pages (conditions générales, confidentialité, contact, confirmation), j'ai adopté une approche modulaire en créant des composants réutilisables et en assurant leur intégration fluide dans l'architecture globale du site web.
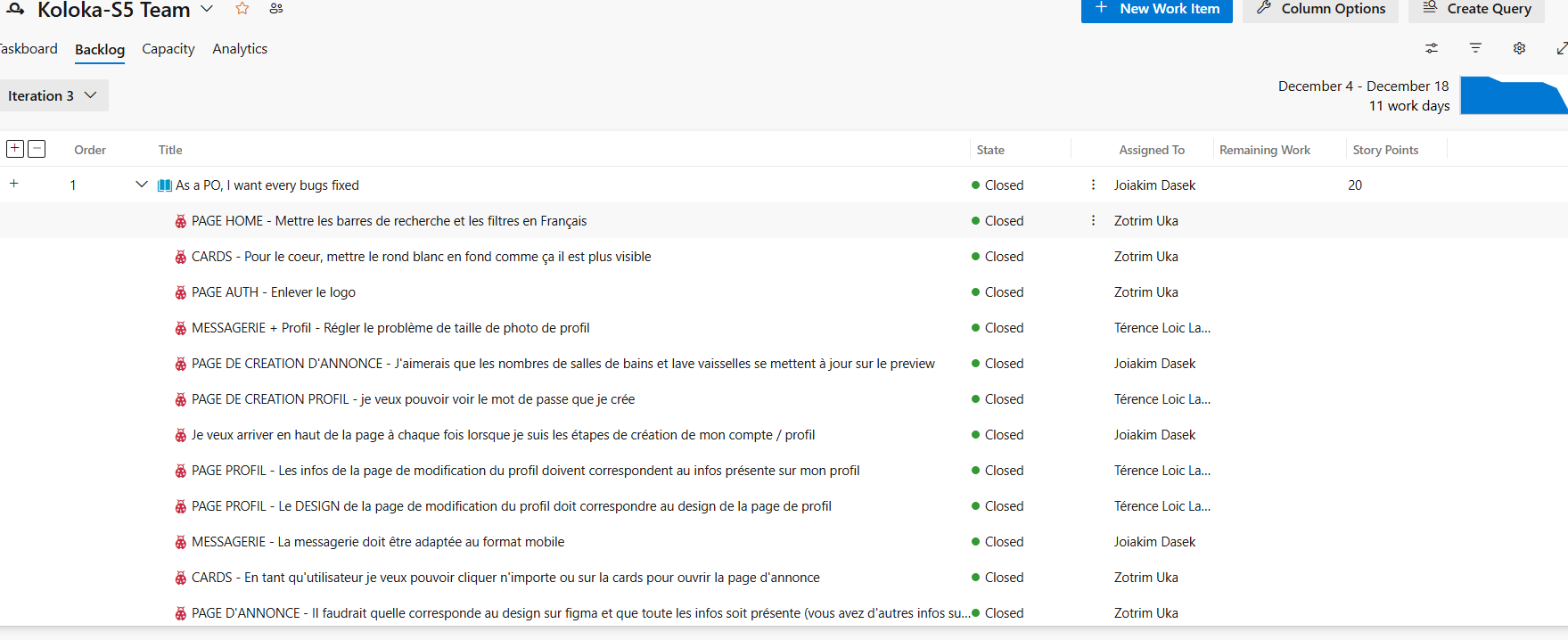 Extrait de mon projet Koloka (méthodologie Scrum)
Extrait de mon projet Koloka (méthodologie Scrum)
 Extrait du composant shadcn que j'ai utilisé, récupéré le 14 janvier 2025 du https://ui.shadcn.com/docs/components/dialog (opens in a new tab)
Extrait du composant shadcn que j'ai utilisé, récupéré le 14 janvier 2025 du https://ui.shadcn.com/docs/components/dialog (opens in a new tab)
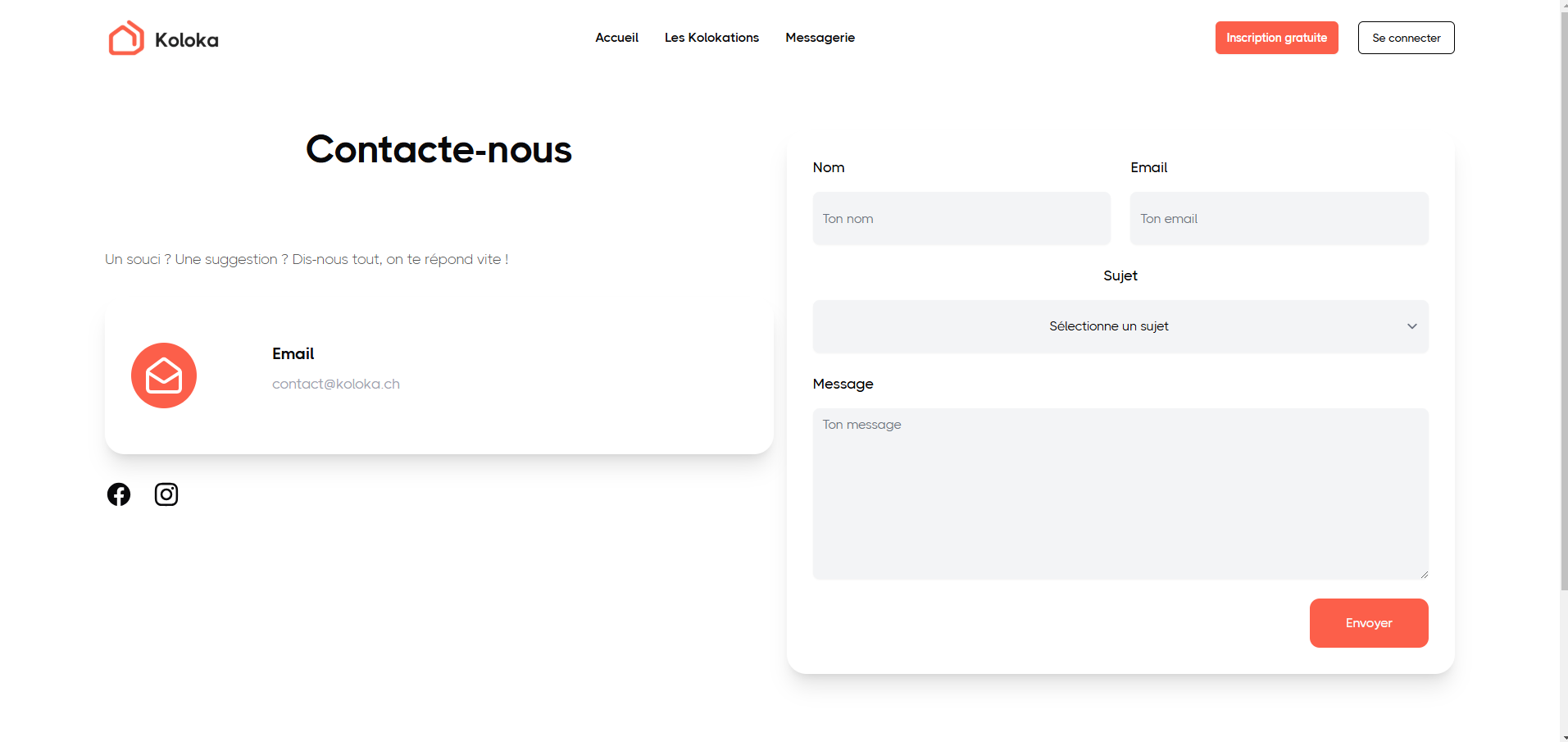 extrait d'une page de Koloka que j'ai implémentée (contact)
extrait d'une page de Koloka que j'ai implémentée (contact)
 extrait d'une page de Koloka que j'ai implémentée (Politique de confidentialité)
extrait d'une page de Koloka que j'ai implémentée (Politique de confidentialité)
 extrait d'une page de Koloka que j'ai implémentée (CGU)
extrait d'une page de Koloka que j'ai implémentée (CGU)
- DevPro : J’ai appliqué la méthodologie Scrum pour structurer le projet, en planifiant les sprints, en créant des User Stories et en attribuant des Story Points. J’ai utilisé des outils adaptés, comme Docker pour tester Milvus, GitHub pour la gestion du code, et des frameworks comme Rasa pour le chatbot. Ces choix méthodologiques et technologiques ont permis de garantir une gestion structurée et efficace du projet. L'infrastructure du projet incluait Next.js, Rasa, Milvus et Docker. J'ai basculé l'hébergement de Railway à Infomaniak pour répondre aux contraintes budgétaires, en maintenant un niveau de performance optimal grâce à l'intégration des outils adaptés.
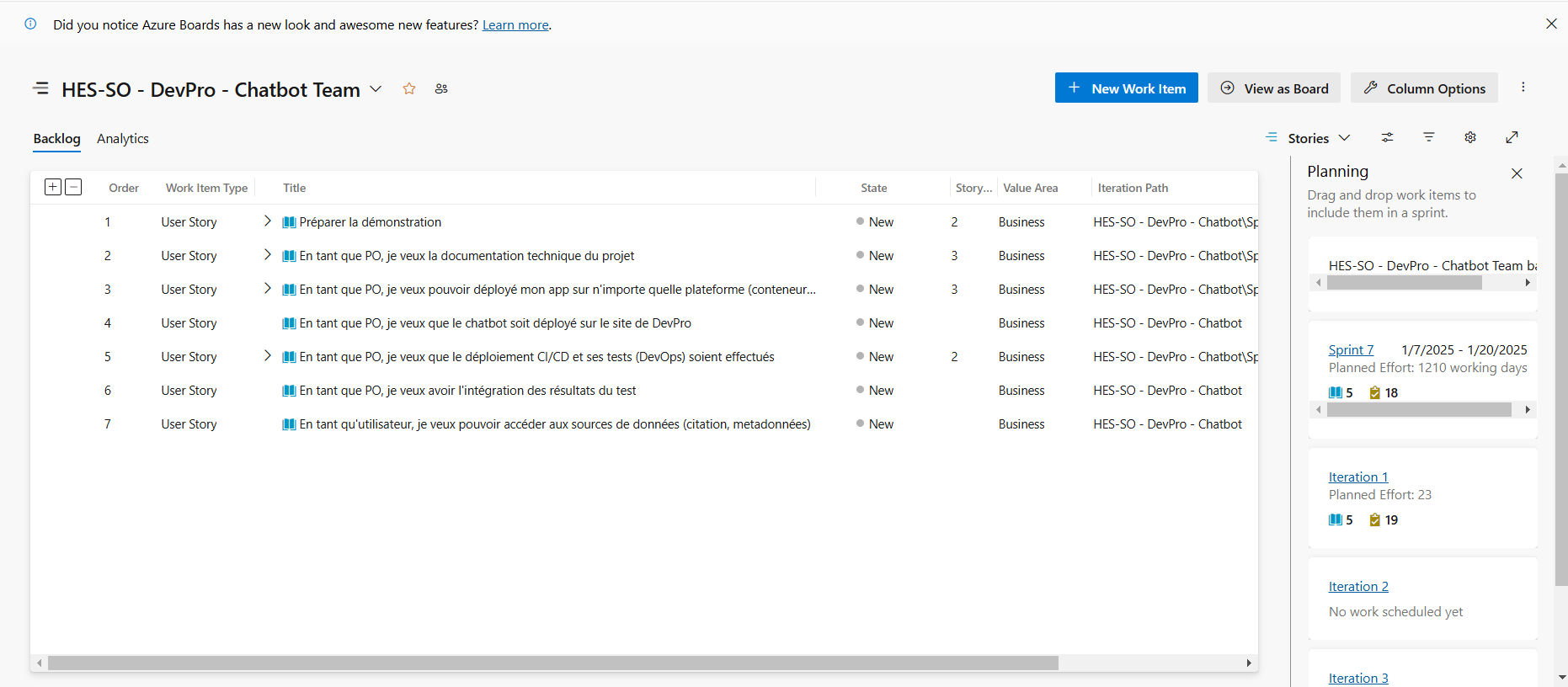 extrait d'azure devops du projet devpro
extrait d'azure devops du projet devpro
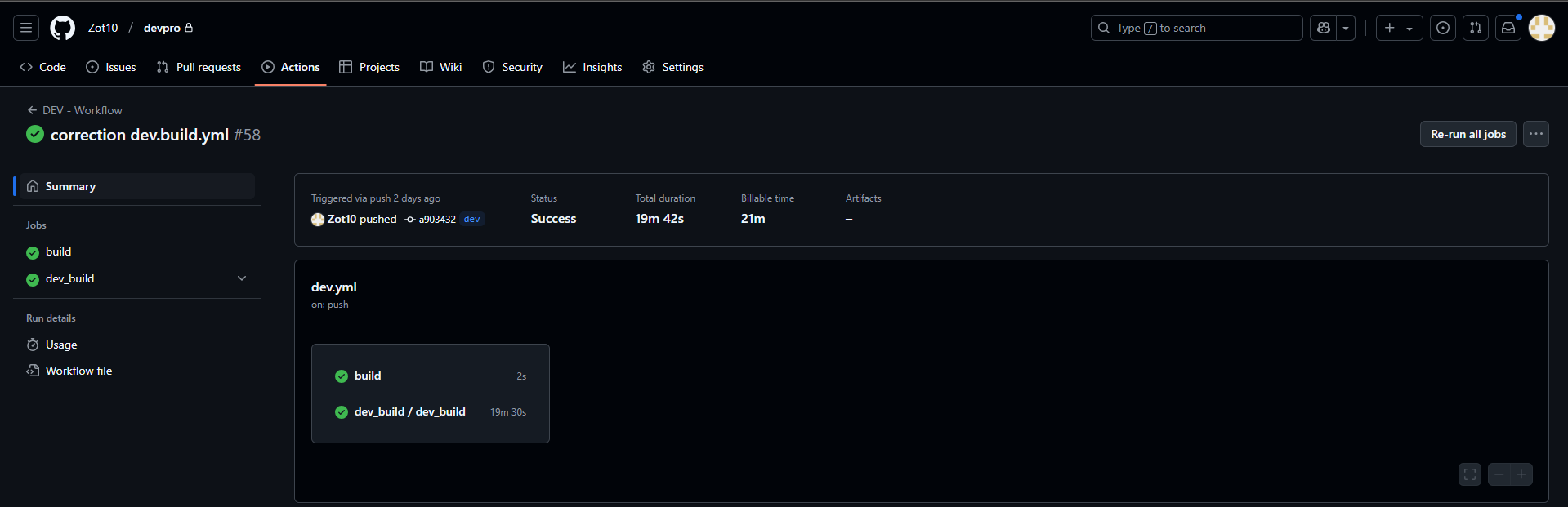 extrait de github actions
extrait de github actions
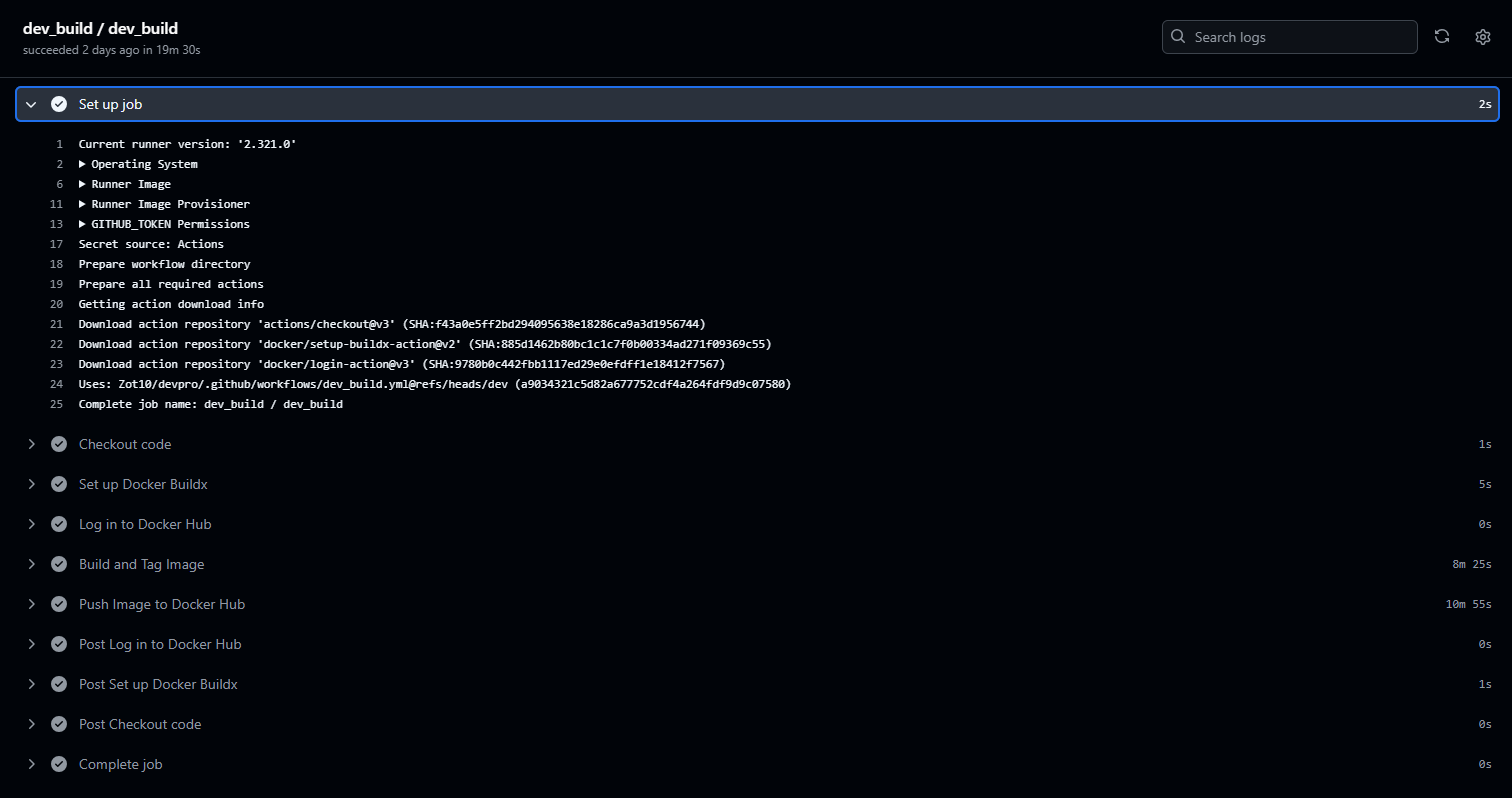 extrait de la pipeline sur github actions
extrait de la pipeline sur github actions
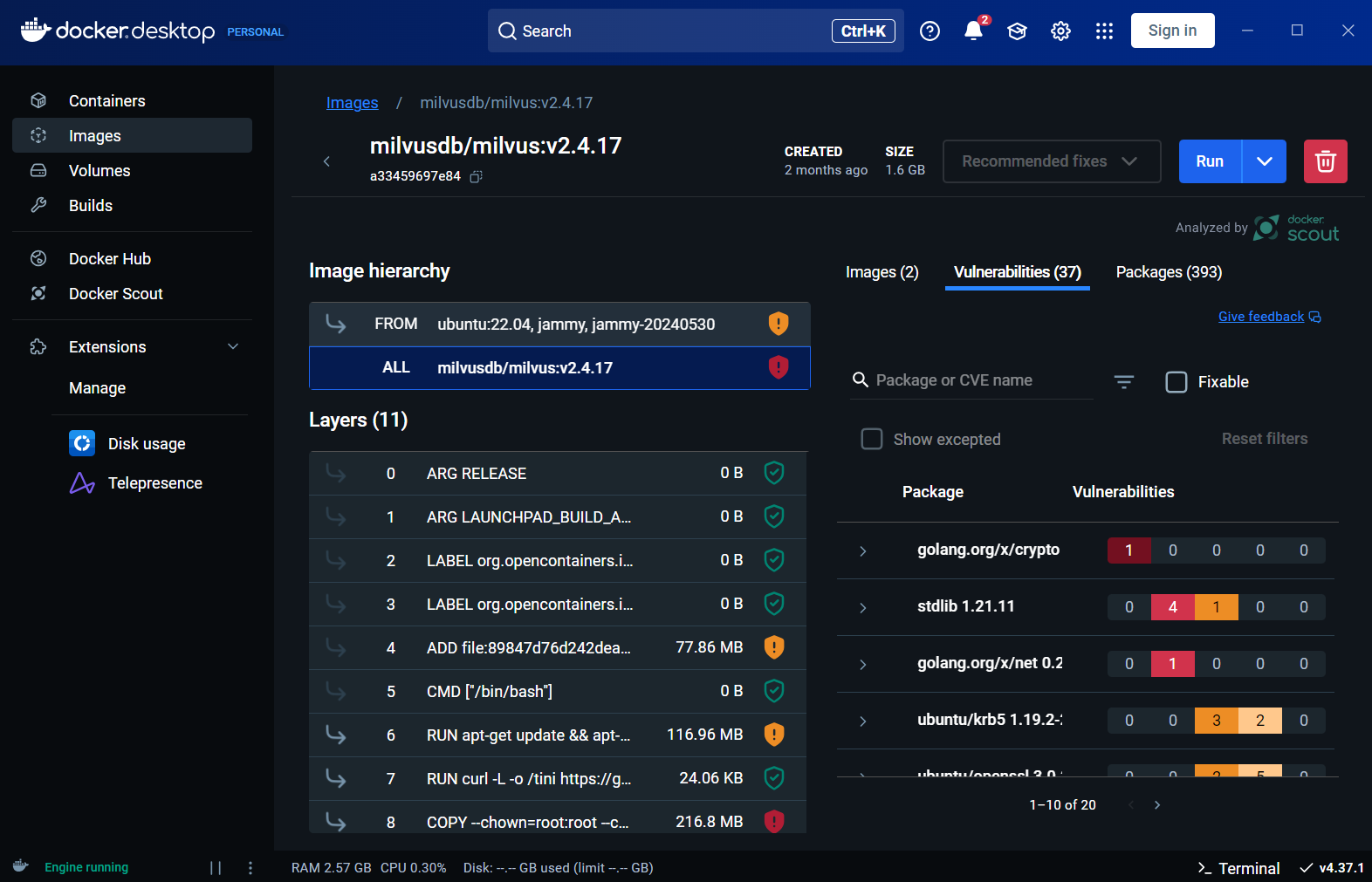 extrait du docker desktop pour utiliser milvus
extrait du docker desktop pour utiliser milvus
 Extrait du de la page du framework Nextjs, récupéré le 14 janvier 2025 du https://nextjs.org/ (opens in a new tab)
Extrait du de la page du framework Nextjs, récupéré le 14 janvier 2025 du https://nextjs.org/ (opens in a new tab)
 Extrait de la page offciel de rasa, Récupéré le 14 janvier 2025 , de https://rasa.com/ (opens in a new tab)
Extrait de la page offciel de rasa, Récupéré le 14 janvier 2025 , de https://rasa.com/ (opens in a new tab)
 Extrait de la page offciel de milvus, Récupéré le 14 janvier 2025 , de https://milvus.io/ (opens in a new tab)
Extrait de la page offciel de milvus, Récupéré le 14 janvier 2025 , de https://milvus.io/ (opens in a new tab)
- CIMO : J’ai appliqué une méthodologie hybride (Scrum + Waterfall) combinée avec des workflows Kanban pour organiser et prioriser les tâches. J’ai utilisé Azure DevOps pour centraliser les contributions de l’équipe, en structurant les tâches et les livrables. Ces outils et méthodologies ont été appliqués de manière efficace pour gérer les flux de travail et répondre aux besoins du client. J'ai également mis en place une organisation basée sur Scrum pour structurer le projet en sprints et décrit les étapes de prétraitement illustrant l'application d'une méthodologie adaptée à un projet utilisant des outils comme Azure DevOps et Microsoft Fabric.
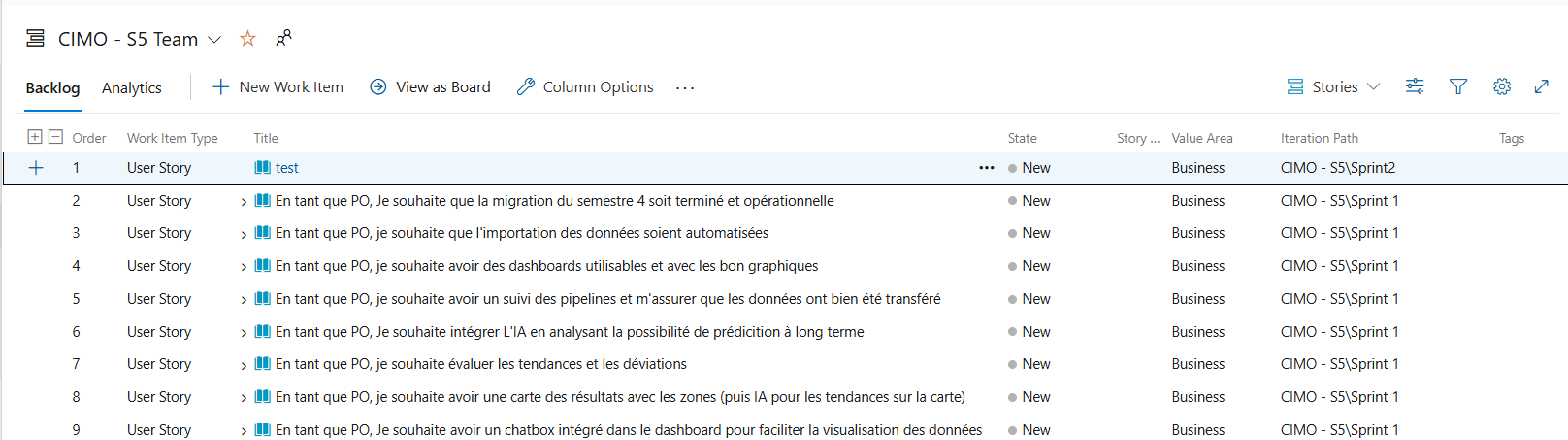 extrait de notre méthodologie agile sur azure devops
extrait de notre méthodologie agile sur azure devops
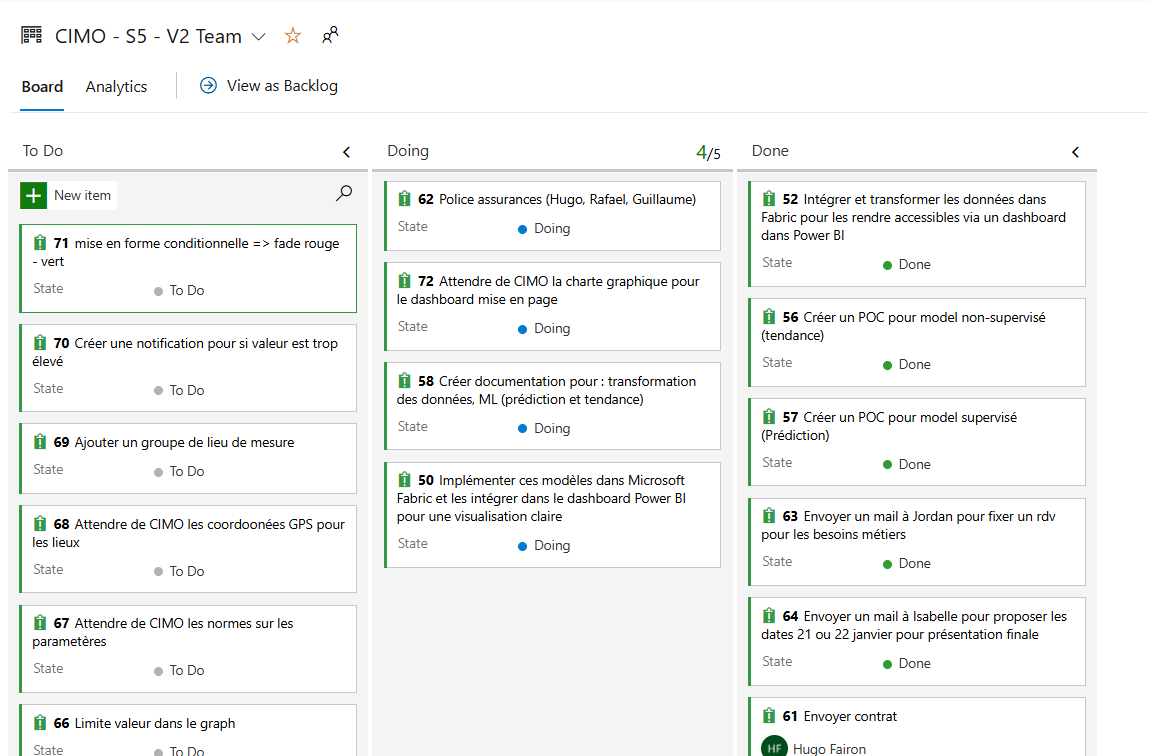 extrait de notre méthodologie hybride sur azure devops
extrait de notre méthodologie hybride sur azure devops
- Infomaniak : J’ai appliqué les bonnes pratiques du développement Angular, en configurant des routes dynamiques, en intégrant un service pour les appels API, et en utilisant Tailwind CSS pour le design. L’utilisation de Cypress pour tester les fonctionnalités principales a permis de valider les flux utilisateur. Ces outils et méthodologies montrent ma capacité à développer une solution fonctionnelle et structurée.
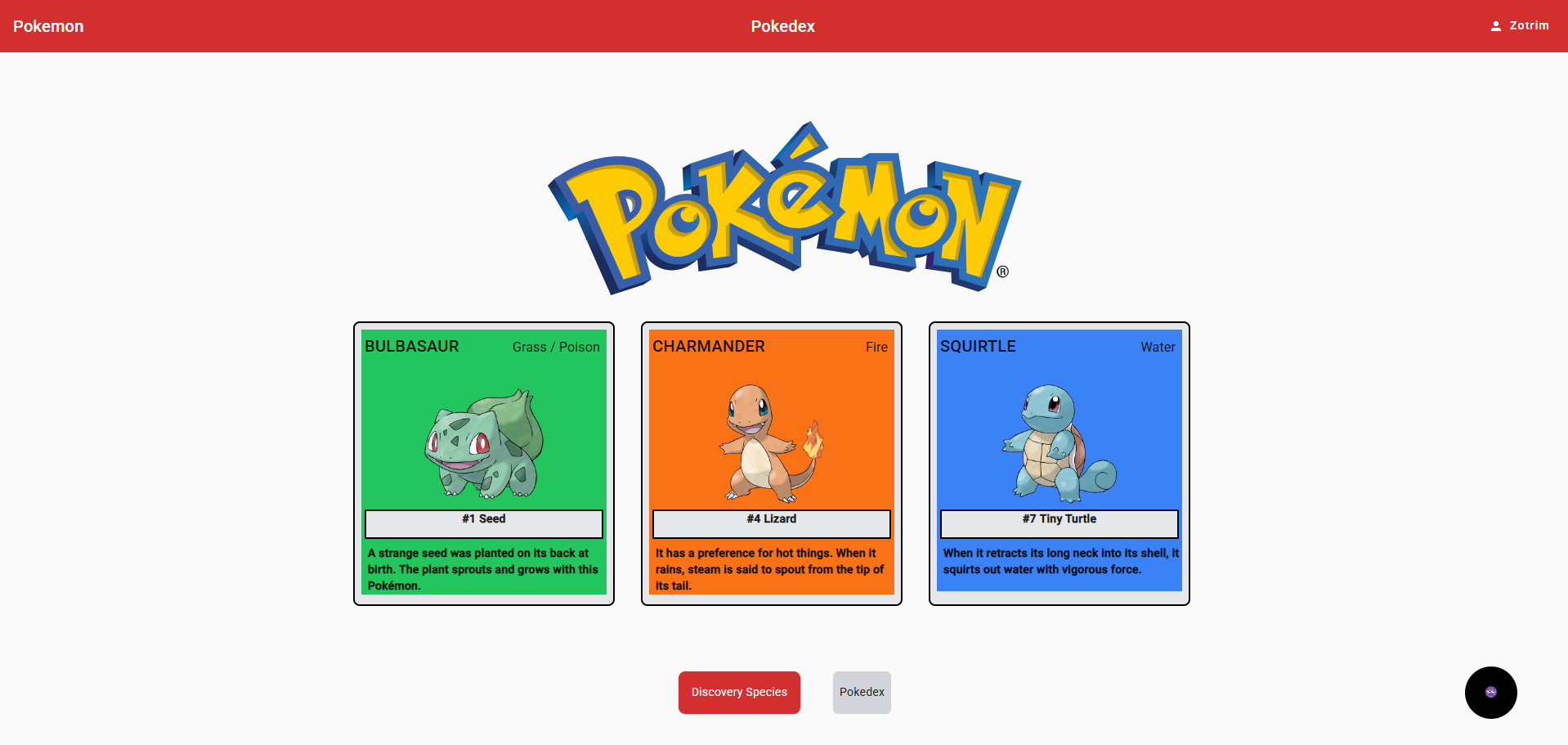 extrait de ma page d'accueil
extrait de ma page d'accueil
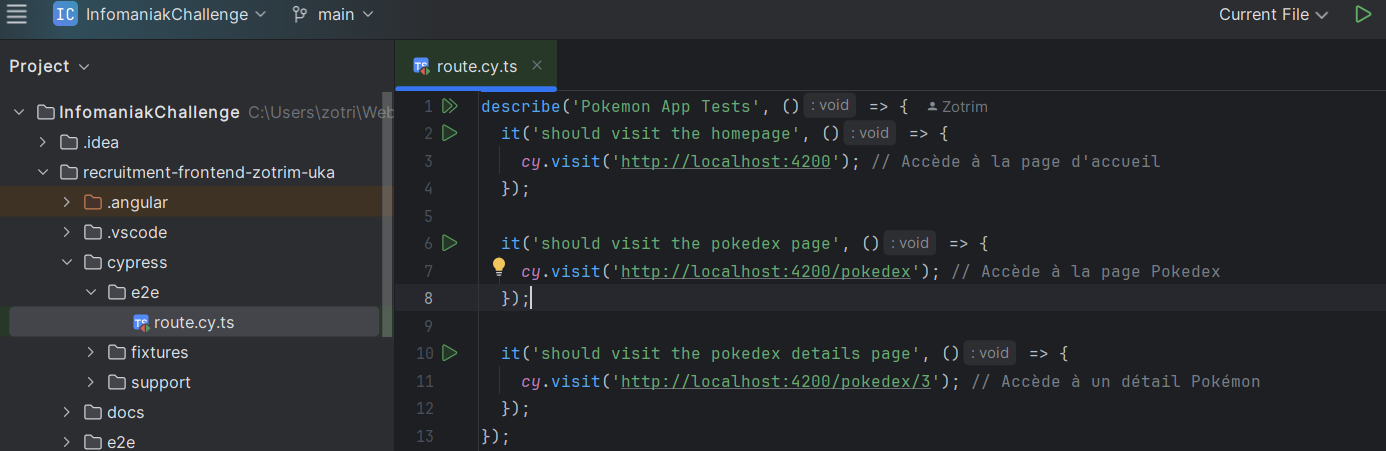 extrait de mon code (cypress) durant le challenge infomaniak
extrait de mon code (cypress) durant le challenge infomaniak
 extrait de mon github pour le challenge infomaniak
extrait de mon github pour le challenge infomaniak
- SF Multiculturalisme : La formation met en avant l’utilisation d'outils numériques, tels que GitHub et des documents centralisés, pour gérer la collaboration à distance. Ces éléments montrent l’importance d'appliquer les bonnes pratiques et technologies pour garantir la continuité et l'efficacité des projets internationaux, en s’adaptant aux besoins des différentes équipes.
- Pourquoi :
Connaître et appliquer des méthodologies adaptées à l'intégration de services dans un écosystème permet de garantir la cohérence et l'efficacité des interactions entre différents systèmes et services. Cela assure une meilleure interopérabilité, optimise les flux de travail et répond aux exigences spécifiques des projets. Une gestion méthodique et adaptée des outils permet également de réduire les erreurs et d'améliorer la performance globale des solutions mises en œuvre.
- Application pratique :
Dans le projet Koloka, l'utilisation de Strapi pour gérer et récupérer les données via des APIs et la création de composants interactifs comme DialogTrigger ont permis une intégration fluide des services front-end dans l'écosystème du projet. Dans le projet DevPro, la gestion des dépendances via Docker, l'utilisation de Rasa pour le chatbot, et la centralisation du code sur GitHub ont illustré ma capacité à structurer un projet utilisant des services variés. Le basculement de l’hébergement de Railway à Infomaniak a démontré ma capacité à adapter l'infrastructure pour répondre aux contraintes techniques et budgétaires tout en maintenant la qualité des services. Dans le projet CIMO, la méthodologie hybride (Scrum + Waterfall) et l’utilisation d'Azure DevOps ont permis de centraliser les contributions de l’équipe et de suivre les étapes critiques du projet de manière structurée.
- Réflexion personnelle :
Ces expériences m'ont appris que le choix des outils et méthodologies doit être en adéquation avec les objectifs et contraintes du projet pour garantir l'efficacité des intégrations. J'ai réalisé que l'approche modulaire et la création de composants réutilisables simplifient l'intégration de nouveaux services et augmentent la maintenabilité du projet. De plus, l'utilisation d'outils collaboratifs comme Azure DevOps m'a permis de structurer efficacement le travail d'équipe et d'optimiser la gestion des ressources dans un écosystème complexe.
Adopter un regard critique sur ces méthodologies et outils
- Quoi :
Cette compétence consiste à évaluer de manière critique les méthodologies et outils utilisés, en examinant leur pertinence, leur efficacité et leurs limites. Elle implique de questionner les pratiques en place pour identifier des améliorations potentielles et adopter les solutions les plus adaptées aux besoins du projet.
- Comment :
- AR 1 : L'article m'a poussé à réfléchir de manière critique à l’utilisation de l'IA dans la préparation des entretiens. J’ai compris que, bien qu'utile, l’IA doit être utilisée de manière complémentaire avec une approche personnelle et authentique. Cette réflexion critique m’aidera à mieux adapter et ajuster mes méthodes à l’avenir.
Extrait de mon ar 1 (page 7)
- Koloka : Lors de la résolution des erreurs liées à Strapi (problèmes de casse des noms générés automatiquement) et des fichiers .env, j'ai analysé et évalué les limites des outils utilisés pour améliorer leur intégration dans le projet. Cette approche critique m'a permis d'optimiser les processus de développement.
- DevPro : J’ai comparé plusieurs approches technologiques pour le projet, comme l’utilisation de RAG et embeddings pour le chatbot, et des frameworks pour le stockage vectoriel comme Milvus. J’ai identifié des limitations, comme les incompatibilités de version entre pdfMiner et d’autres frameworks, et proposé des ajustements pour optimiser leur utilisation. Cette analyse critique m’a permis d’améliorer les processus et d’assurer leur adéquation au projet.
- CIMO : J’ai évalué l’efficacité de Scrum dans le cadre du projet et proposé une transition vers une gestion hybride pour répondre aux exigences spécifiques. J’ai également analysé les outils utilisés, comme les tableaux de bord, en identifiant des points d’amélioration.
extrait de notre méthodologie hybride transition d'une méthodologie agile (SCRUM)
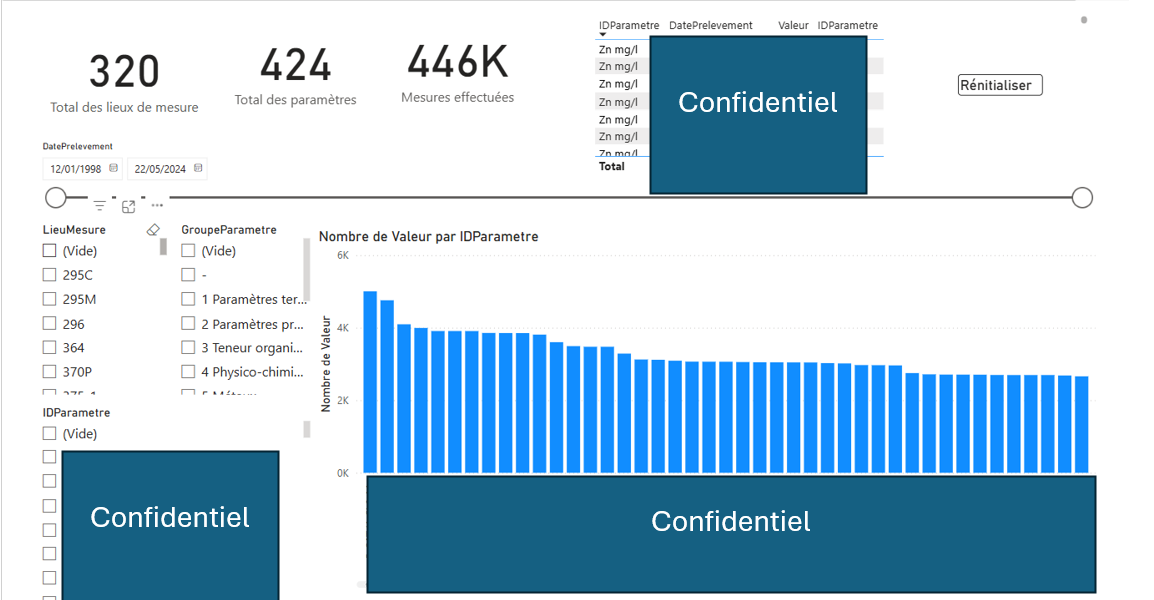 extrait du dashboard du projet CIMO
extrait du dashboard du projet CIMO
- Infomaniak : J’ai constaté les limites de l’automatisation des tests avec Cypress, en particulier dans un délai restreint, et réfléchi à des améliorations potentielles comme l’intégration de NgRx pour la gestion des états. Cette analyse critique m’a permis d’évaluer les outils et méthodologies utilisés pour mieux les exploiter à l’avenir.
extrait de mon code (cypress) durant le challenge infomaniak
- SF-ML : La mise en garde sur les modèles sur-ajustés (overfitting) et la nécessité d’interpréter les résultats selon le contexte montrent une capacité à évaluer les limites des outils et à ajuster leur utilisation.
- Pourquoi :
Adopter un regard critique sur les méthodologies et outils permet d'identifier leurs points faibles et de proposer des ajustements pour optimiser leur utilisation. Cette démarche améliore la qualité des livrables et permet de choisir des solutions adaptées aux contraintes du projet. Cela favorise également l'évolution continue des pratiques, en évitant une utilisation systématique sans réflexion des outils disponibles, et contribue à améliorer la prise de décision dans les phases clés du projet.
- Application pratique :
Dans le projet DevPro, l'analyse comparative entre l'approche RAG et l'utilisation d'embeddings dans la recherche d'information, ainsi que des frameworks de stockage vectoriel comme Milvus, m'a permis de choisir une solution adaptée aux besoins du projet tout en proposant des alternatives en cas de limitations techniques. Dans CIMO, l’évaluation des limites de Scrum dans le contexte du projet a conduit à la mise en place d'une méthodologie hybride, combinant des aspects waterfall et Kanban, ce qui a permis de mieux structurer les phases critiques. Enfin, pour Infomaniak, j'ai évalué l'efficacité de Cypress pour les tests automatisés et constaté les limites en termes de profondeur de tests sur les états dynamiques. Cela m'a permis de réfléchir à l'intégration d'outils supplémentaires comme NgRx pour une meilleure gestion des états.
- Réflexion personnelle :
Ces expériences m'ont montré l'importance de ne pas se contenter des pratiques établies et d'évaluer constamment leur pertinence en fonction des besoins du projet. J'ai compris que chaque outil ou méthodologie présente des avantages et des inconvénients qu'il est essentiel de prendre en compte pour proposer des solutions optimisées. Cette approche critique m'a également permis de développer une meilleure capacité à anticiper les limites potentielles et à adapter mes choix pour assurer la continuité et la performance des projets.
Connaître les principaux concepts mathématiques nécessaires à la Data Science et savoir les appliquer dans un cas d’utilisation du Machine Learning
- Quoi :
Cette compétence consiste à maîtriser les concepts mathématiques fondamentaux—statistiques, probabilités, algèbre linéaire et calcul—et à les appliquer efficacement dans des cas pratiques de Machine Learning.
- Comment :
- DevPro : J’ai travaillé sur les concepts mathématiques liés aux vecteurs et à leur stockage dans Milvus, notamment les collections, les dimensions et les index. J’ai appliqué ces concepts pour gérer des données vectorielles, en les intégrant dans une base de données adaptée aux besoins du projet. Ces connaissances ont été essentielles pour optimiser les performances du chatbot.
from pymilvus import connections, Collection, CollectionSchema, FieldSchema, DataType
import numpy as np
# Se connecter au client Milvus
connections.connect(host='localhost', port='19530')
print("Connexion réussie au serveur Milvus")
# Définir les champs de la collection
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=True),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=128)
]
# Créer le schéma de la collection
schema = CollectionSchema(fields, description="Exemple de collection")
# Créer la collection
collection = Collection("exemple_collection", schema)
# Générer des données
data = np.random.rand(100, 128).tolist() # 100 vecteurs de 128 dimensions
# Insérer les données dans la collection
collection.insert([data]) # Insérer uniquement les vecteurs 'embedding'
# Charger la collection en mémoire
collection.load()
# Vérifier le nombre d'entités dans la collection
print(f"Nombre d'entités dans la collection : {collection.num_entities}")- CIMO : J’ai appliqué des concepts mathématiques liés aux modèles supervisés (Random Forest) et non supervisés (K-Means), comme le calcul des distances entre points dans un espace vectoriel pour le clustering et l’évaluation de la performance des prédictions avec la métrique RMSE. Ces concepts ont été utilisés pour résoudre des problématiques métiers concrètes et enrichir les analyses des données environnementales.
Modèle supervisé : Random Forest
# Importation des bibliothèques pour le modèle Random Forest et l'évaluation des performances
from pyspark.ml.regression import RandomForestRegressor
from pyspark.ml.evaluation import RegressionEvaluator
# Initialisation du modèle Random Forest avec 50 arbres de décision
rf = RandomForestRegressor(featuresCol="features", labelCol="confidentiel", numTrees=50)
# Entraînement du modèle sur les données d'entraînement
model = rf.fit(train_data)
# Prédictions sur les données de test
predictions = model.transform(test_data)
# Calcul de l'erreur quadratique moyenne (RMSE) pour évaluer la précision des prédictions
evaluator = RegressionEvaluator(labelCol="confidentiel", predictionCol="prediction", metricName="rmse")
rmse = evaluator.evaluate(predictions)
print(f"Root Mean Squared Error (RMSE): {rmse}") # Affichage du RMSE pour mesurer l'écart moyen entre les valeurs prédites et réellesModèle K-Means (non supervisé - clustering) : python
# Importation des bibliothèques pour le clustering K-Means
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.clustering import KMeans
# Préparation des données pour le modèle : création d'un vecteur de caractéristiques
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
df_transformed = assembler.transform(df_filled)
# Initialisation du modèle K-Means avec 3 clusters
kmeans = KMeans(k=3, seed=42, featuresCol="features")
# Entraînement du modèle K-Means sur les données transformées
model = kmeans.fit(df_transformed)
# Application du modèle pour obtenir les clusters attribués à chaque point
df_clustered = model.transform(df_transformed)
# Visualisation des clusters sur un scatter plot
import matplotlib.pyplot as plt
df_pandas = df_clustered.select("TEMPERATURE", "OXYGENE", "cluster").toPandas()
plt.figure(figsize=(8, 6))
for cluster in df_pandas["cluster"].unique():
cluster_data = df_pandas[df_pandas["cluster"] == cluster]
plt.scatter(cluster_data["TEMPERATURE"], cluster_data["OXYGENE"], label=f"Cluster {cluster}") # Affichage des clusters sur la base des distances entre points
plt.xlabel("Temperature") # Axe des X : température
plt.ylabel("Oxygen") # Axe des Y : oxygène
plt.title("Clustering with K-Means") # Titre du graphe
plt.legend() # Affichage de la légende des clusters
plt.show()- SF-ML : La session a démontré l'utilisation de bibliothèques comme Scikit-Learn pour tester rapidement différents algorithmes sur des jeux de données, illustrant ainsi l'application pratique des outils de machine learning dans des projets réels.
- Cours youtube (Math) (opens in a new tab) : Lors du cours de mathématiques sur les statistiques, j'ai acquis des connaissances essentielles pour la Data Science, telles que la moyenne, la médiane, la variance et l'écart-type, qui permettent de comprendre la répartition des données et de détecter des anomalies.
lien du cours sur youtube : https://www.youtube.com/watch?v=EpEZbbHeR7I&t=12s&ab_channel=Elkhader (opens in a new tab) 5. Apple Watch : J'ai pris l'initiative d'extraire les données de mon Apple Watch concernant uniquement le rythme cardiaque pour m'entraîner à construire des modèles de machine learning supervisé et non supervisé. J'ai nettoyé et préparé ces données, puis expérimenté avec différents algorithmes pour effectuer des prédictions et des regroupements. Cette démarche personnelle démontre ma capacité à apprendre de manière autonome et à me perfectionner dans l'application pratique de l'intelligence artificielle.
Modèle K-Means :
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
from sklearn.ensemble import IsolationForest
import matplotlib.pyplot as plt
def unsupervised_analysis(file="final_data.csv"):
df = pd.read_csv(file)
if "BPM" not in df.columns:
print("Colonne BPM introuvable dans le fichier.")
return
# Création de quelques features
df["BPM_diff"] = df["BPM"].diff().fillna(0)
df["BPM_rolling_mean"] = df["BPM"].rolling(window=5, min_periods=1).mean()
df["BPM_rolling_std"] = df["BPM"].rolling(window=5, min_periods=1).std().fillna(0)
df.dropna(inplace=True)
features = ["BPM", "BPM_diff", "BPM_rolling_mean", "BPM_rolling_std"]
X = df[features].values
# 1) Clustering (K-Means)
k = 3 # Nombre de clusters
kmeans = KMeans(n_clusters=k, random_state=42)
df["Cluster"] = kmeans.fit_predict(X)
print("\n--- Clustering K-Means ---")
print(df.groupby("Cluster")[features].mean())
# Visualisation simple (sur 2 features pour un scatterplot)
plt.figure(figsize=(7, 5))
plt.scatter(df["BPM"], df["BPM_rolling_mean"], c=df["Cluster"], cmap="viridis")
plt.title("K-Means: BPM vs. BPM_rolling_mean")
plt.xlabel("BPM")
plt.ylabel("BPM Rolling Mean")
plt.grid(True)
plt.show()
# 2) Détection d'anomalies (IsolationForest)
iso = IsolationForest(contamination=0.01, random_state=42)
iso.fit(X)
df["anomaly_score"] = iso.decision_function(X)
df["is_anomaly"] = iso.predict(X) # 1 = normal, -1 = anomalie
anomalies = df[df["is_anomaly"] == -1]
print("\n--- Anomalies détectées ---")
print(anomalies.head())
print(f"Nombre total d'anomalies: {len(anomalies)}")
# Visualisation des anomalies
plt.figure(figsize=(10, 4))
plt.plot(df.index, df["BPM"], label="BPM", color="blue")
plt.scatter(anomalies.index, anomalies["BPM"], color="red", label="Anomalies")
plt.title("Détection d'anomalies (IsolationForest)")
plt.xlabel("Index")
plt.ylabel("BPM")
plt.legend()
plt.grid(True)
plt.show()
# Appel de la fonction
unsupervised_analysis("final_data.csv") Extrait de mon modèle non-supervisé (K-Means)
Extrait de mon modèle non-supervisé (K-Means)
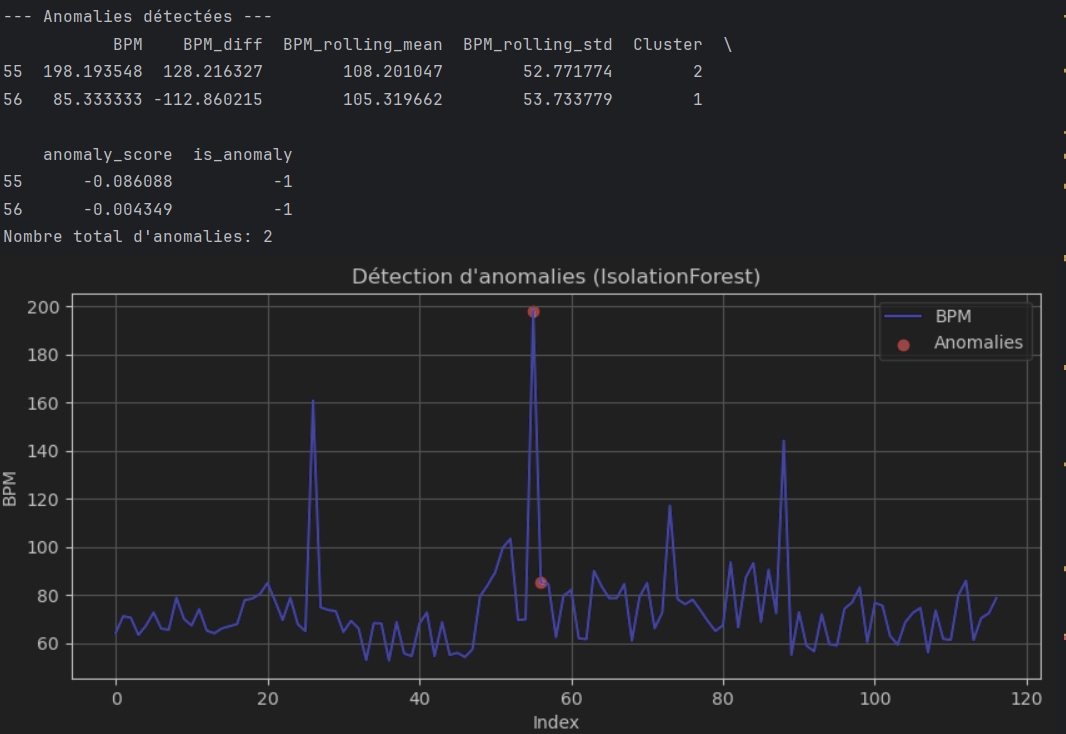 Extrait de mon modèle non-supervisé (K-Means)
Extrait de mon modèle non-supervisé (K-Means)
Je pense que le modèle K-Means peut être intéressant pour avoir une première exploration des données BPM provenant de mon Apple Watch, mais il n’est pas forcément le plus adapté. Les variations de BPM sont souvent influencées par des facteurs temporels comme l'activité physique ou le stress, ce qui rend les hypothèses du K-Means (clusters sphériques et homogènes) moins pertinentes. Je pourrais envisager des modèles plus adaptés aux séries temporelles, comme ARIMA ou des réseaux neuronaux récurrents, pour mieux capturer les variations et les comportements complexes de mes données.
Modèle Regression Linéaire :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import TimeSeriesSplit, GridSearchCV
from sklearn.metrics import mean_squared_error, r2_score
def create_time_features(df, max_lag=3, rolling_window=5):
"""
Crée des features basées sur le BPM :
1) Lags multiples (BPM_lag1, BPM_lag2, etc.)
2) Rolling mean et rolling std sur une fenêtre donnée
3) BPM_diff (différence entre t et t-1)
4) BPM_future (décalage de -1 pour prédire le BPM suivant)
"""
# 1) Création des lags
for lag in range(1, max_lag+1):
df[f"BPM_lag{lag}"] = df["BPM"].shift(lag)
# 2) Rolling mean et std
df["BPM_rolling_mean"] = df["BPM"].rolling(window=rolling_window, min_periods=1).mean()
df["BPM_rolling_std"] = df["BPM"].rolling(window=rolling_window, min_periods=1).std().fillna(0)
# 3) Différence instantanée
df["BPM_diff"] = df["BPM"].diff().fillna(0)
# 4) Cible : BPM du point suivant
df["BPM_future"] = df["BPM"].shift(-1)
# Supprimer les lignes NaN (en particulier les premières lignes à cause des lags
# et la dernière pour BPM_future)
df.dropna(inplace=True)
return df
def train_test_split_time_based(df, split_ratio=0.8):
"""
Sépare chronologiquement le dataset :
- train = 0 à split_index
- test = split_index à fin
"""
split_index = int(len(df) * split_ratio)
train_df = df.iloc[:split_index].copy()
test_df = df.iloc[split_index:].copy()
return train_df, test_df
def supervised_regression_time_series(
file_path="final_data.csv",
max_lag=3,
rolling_window=5,
split_ratio=0.8,
use_gridsearch=False
):
"""
Pipeline complet :
1) Lecture du CSV contenant une colonne 'BPM'
2) Création de features (lags, rolling, diff, BPM_future)
3) Split train/test chronologique
4) Entraînement d'un RandomForestRegressor
(option GridSearchCV pour ajuster hyperparamètres)
5) Prédiction + Évaluation (MSE, R2)
6) Visualisation (courbes y_test vs y_pred)
"""
# 1) Lecture des données
df = pd.read_csv(file_path)
if "BPM" not in df.columns:
print("Erreur : colonne 'BPM' introuvable dans le fichier.")
return None
# 2) Création des features
df = create_time_features(df, max_lag=max_lag, rolling_window=rolling_window)
# 3) Split chronologique
train_df, test_df = train_test_split_time_based(df, split_ratio=split_ratio)
# 4) Préparation X, y
feature_cols = [col for col in train_df.columns
if col not in ("BPM_future", "BPM", "datetime")] # exclure BPM si besoin
# Exemple : on garde BPM + BPM_lag1..n, BPM_rolling_mean, BPM_rolling_std, BPM_diff
X_train = train_df[feature_cols].values
y_train = train_df["BPM_future"].values
X_test = test_df[feature_cols].values
y_test = test_df["BPM_future"].values
# Modèle
model = RandomForestRegressor(n_estimators=100, random_state=42)
if use_gridsearch:
# Exemple d'espace d'hyperparamètres
param_grid = {
'n_estimators': [50, 100, 200],
'max_depth': [None, 10, 20],
'min_samples_leaf': [1, 2, 5]
}
# On utilise TimeSeriesSplit pour rester cohérent
tscv = TimeSeriesSplit(n_splits=3)
grid_search = GridSearchCV(
estimator=model,
param_grid=param_grid,
scoring='r2',
cv=tscv,
n_jobs=-1
)
grid_search.fit(X_train, y_train)
print("Meilleurs paramètres (GridSearch) :", grid_search.best_params_)
model = grid_search.best_estimator_
else:
model.fit(X_train, y_train)
# 5) Prédiction et évaluation
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("=== Évaluation (portion Test) ===")
print(f" - MSE = {mse:.3f}")
print(f" - R^2 = {r2:.3f}")
# 6) Visualisation simple
plt.figure(figsize=(10, 5))
plt.plot(test_df.index, y_test, label="BPM futur (réel)", color='blue')
plt.plot(test_df.index, y_pred, label="BPM prédit", color='orange')
plt.title("Comparaison du BPM réel vs. prédiction (Test set)")
plt.xlabel("Index (temps)")
plt.ylabel("BPM")
plt.legend()
plt.grid(True)
plt.show()
return model
if __name__ == "__main__":
model = supervised_regression_time_series(
file_path="final_data.csv",
max_lag=3,
rolling_window=5,
split_ratio=0.8,
use_gridsearch=False
)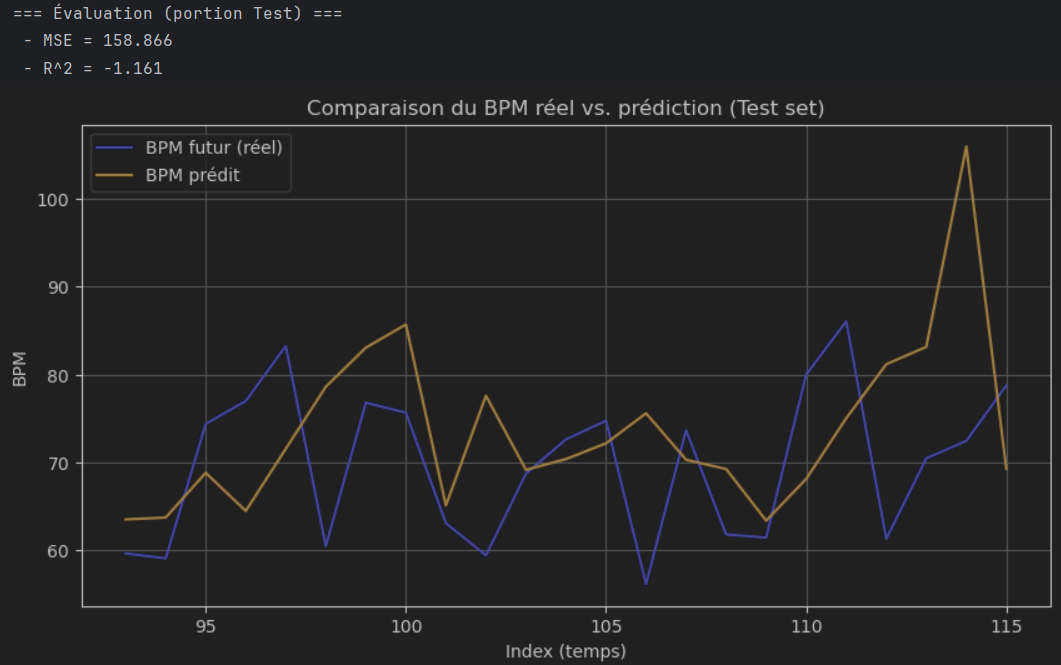 Extrait de mon modèle supervisé régression linéaire
Extrait de mon modèle supervisé régression linéaire
Je pense que ce modèle est bien adapté pour prédire les BPM à partir des données de mon Apple Watch. Il utilise des caractéristiques temporelles pertinentes et un Random Forest pour fournir des prédictions fiables. Cependant, des modèles plus avancés comme les LSTM pourraient mieux capturer les dynamiques complexes des séries temporelles.
modèle DBSCAN :
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
def create_features_for_clustering(df):
"""
Exemple de fonction pour sélectionner ou créer quelques features
pour un clustering non supervisé (DBSCAN).
Suppose qu'on a déjà une colonne 'BPM' dans df.
"""
# On peut garder seulement la colonne BPM ou ajouter d'autres features
# (rolling mean, diff, etc.) si on veut un clustering plus riche.
# Par exemple :
df["BPM_diff"] = df["BPM"].diff().fillna(0)
df["BPM_rolling_mean"] = df["BPM"].rolling(window=5, min_periods=1).mean()
df["BPM_rolling_std"] = df["BPM"].rolling(window=5, min_periods=1).std().fillna(0)
df.dropna(inplace=True)
# Sélection des features pour le clustering
features = ["BPM", "BPM_diff", "BPM_rolling_mean", "BPM_rolling_std"]
return df[features]
def dbscan_clustering(file_path="final_data.csv", eps=5, min_samples=5):
"""
1) Lecture du CSV contenant 'BPM'
2) Création/ sélection de features
3) Standardisation des données
4) Application DBSCAN
5) Affichage du nombre de clusters et visualisation
"""
# 1) Lecture
df = pd.read_csv(file_path)
if "BPM" not in df.columns:
print("Colonne BPM introuvable. Vérifiez votre fichier.")
return
# 2) Création/ sélection de features
X = create_features_for_clustering(df)
# X est un DataFrame avec columns = [BPM, BPM_diff, BPM_rolling_mean, BPM_rolling_std, ...]
# 3) Standardisation
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 4) DBSCAN
# eps = distance max pour former un cluster
# min_samples = nombre minimum de points pour être considéré comme cluster dense
dbscan = DBSCAN(eps=eps, min_samples=min_samples)
clusters = dbscan.fit_predict(X_scaled)
# Ajout du cluster dans le DataFrame
X["Cluster"] = clusters
# 5) Affichage
# Nombre de clusters trouvés (valeur -1 = bruit / outlier)
cluster_labels = np.unique(clusters)
n_clusters = len(cluster_labels[cluster_labels != -1]) # on exclut le -1 (bruit)
print(f"Nombre de clusters (hors bruit) = {n_clusters}")
print(f"Labels de clusters trouvés = {cluster_labels}")
print(X.groupby("Cluster").mean())
# Visualisation 2D (on ne peut tracer que 2 features à la fois)
# Exemple : BPM vs BPM_diff colorés par cluster
plt.figure(figsize=(8, 6))
plt.scatter(X["BPM"], X["BPM_diff"], c=X["Cluster"], cmap="rainbow", s=20)
plt.title("DBSCAN Clustering : BPM vs BPM_diff")
plt.xlabel("BPM")
plt.ylabel("BPM_diff")
plt.colorbar(label="Cluster")
plt.show()
return X # on retourne le DataFrame avec la colonne "Cluster"
if __name__ == "__main__":
result = dbscan_clustering(
file_path="final_data.csv",
eps=5, # Distance maximale pour la densité
min_samples=5 # Nombre min de points dans le voisinage pour former un cluster
)
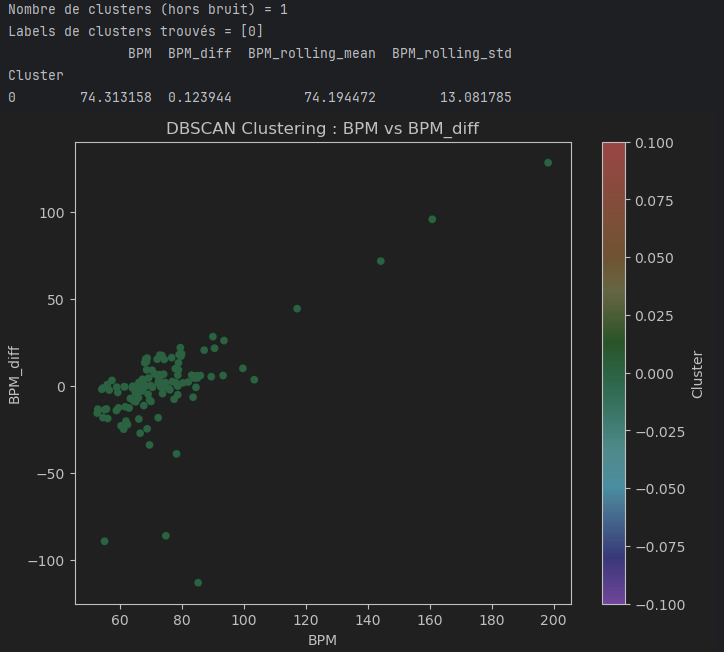 Extrait de mon modèle non-supervisé (DBSCAN)
Extrait de mon modèle non-supervisé (DBSCAN)
Je pense que ce modèle utilisant DBSCAN est bien adapté pour explorer les données BPM de mon Apple Watch. Contrairement à K-Means, il détecte des clusters de formes arbitraires et identifie les points isolés comme du bruit, ce qui convient bien aux données biométriques souvent hétérogènes.
- LI IA (Camarade): La lecture de L’intelligence artificielle expliquée m’a permis de comprendre les concepts fondamentaux de l’IA et du machine learning, notamment les approches supervisées, non supervisées et par renforcement. Ce livre met en lumière l’impact stratégique des technologies d’IA sur les entreprises, telles que l’automatisation des processus, l’optimisation des flux de travail et la personnalisation des services. Les sections sur les GANs et les Transformers expliquent comment ces modèles innovants influencent les systèmes d’information modernes pour améliorer leur efficacité et leur compétitivité
- LI ML (Camarade) : Ce document présente une initiation complète au Machine Learning, abordant des thématiques telles que la gestion des datasets, les étapes de développement d’un modèle prédictif et l’importance de l’évaluation des performances. Il met également l’accent sur les méthodologies nécessaires pour intégrer des modèles ML dans les systèmes d’information d’entreprise, renforçant leur capacité à traiter et analyser des données massives pour prendre des décisions éclairées.
- Pourquoi :
La maîtrise des concepts mathématiques est essentielle pour comprendre et appliquer efficacement les algorithmes de machine learning. Cela permet de choisir les modèles adaptés aux données, d'interpréter les résultats de manière pertinente et d'améliorer les performances en ajustant les paramètres sur des bases solides. Ces compétences mathématiques sont également indispensables pour détecter et corriger les biais potentiels dans les données ou les prédictions, garantissant ainsi des analyses fiables et précises.
- Application pratique :
Dans le projet DevPro, j'ai manipulé des vecteurs dans Milvus pour stocker et gérer des données vectorielles, en comprenant les notions de collections et de dimensions sans nécessairement optimiser leur structure, mais en assurant leur intégration dans le workflow du chatbot. Dans le projet CIMO, j'ai utilisé des notions mathématiques comme le calcul des distances dans l'espace vectoriel pour appliquer le clustering K-Means, sans entrer dans des calculs approfondis, et la métrique RMSE m'a permis d'évaluer la fiabilité des prédictions de Random Forest de manière pratique. Enfin, le cours sur les statistiques m'a permis de renforcer ma compréhension de la moyenne, la médiane, la variance et l'écart-type, ce qui m'a aidé à analyser la répartition des données, notamment dans le projet CIMO pour interpréter les valeurs environnementales.
- Réflexion personnelle :
Ces expériences m'ont permis de réaliser l'importance de comprendre les fondements mathématiques pour expliquer les comportements des modèles de machine learning et améliorer leur fiabilité. J'ai également compris que la maîtrise des statistiques et des calculs algébriques permet d'aller au-delà de l'utilisation d'outils standards pour personnaliser et affiner les algorithmes en fonction des besoins métiers. Cela m'a encouragé à continuer à approfondir mes connaissances pour mieux adapter les modèles aux problématiques réelles rencontrées dans mes projets.